Hi,
I have created a simple linear regression model. It runs fine with cpu but when I run the model on gpu it does not fit the model at all. Can some one find out any mistake I have done.
Here is a simple model definition. Its is just a test code nothing for production:
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
np.random.seed(103)
def generate_1d_data():
features = np.linspace(0, 20, num=200)
targets = features + np.sin(features) * 2 + np.random.normal(size=features.shape)
return features, targets
class LinearRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
def get_device(device='cuda'):
if device == 'cpu':
return torch.device('cpu')
return torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def get_prediction(model, device, inputs):
with torch.no_grad():
preds = model(inputs.to(device)).cpu().numpy()
return preds
def train(model, device, inputs, labels, epochs):
model.to(device)
for epoch in range(epochs):
print(f'Epoch {epoch}')
optimizer.zero_grad()
outputs = model(inputs.to(device))
loss = criterion(outputs, labels.to(device))
loss.backward()
optimizer.step()
return loss
X, y = generate_1d_data()
inputs = torch.tensor(X.reshape(-1, 1), dtype=torch.float32)
labels = torch.tensor(y.reshape(-1, 1), dtype=torch.float32)
criterion = nn.MSELoss()
Running with CPU and GPU is as follows:
# Running with CPU
model = LinearRegressionModel(input_dim=1, output_dim=1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
device = get_device('cpu')
loss = train(model, device, inputs, labels, epochs=2000)
print("loss:", loss.data.cpu().numpy())
m = model.linear.weight.data.cpu().numpy()[0][0]
b = model.linear.bias.data.cpu().numpy()[0]
print("m(slope)=", m, "n(y-intercept)=", b)
predictions_cpu = get_prediction(model, device, inputs)
# Running with GPU
model = LinearRegressionModel(input_dim=1, output_dim=1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
device_gpu = get_device()
loss = train(model, device_gpu, inputs, labels, epochs=2000)
print("loss:", loss.data.cpu().numpy())
m = model.linear.weight.data.cpu().numpy()[0][0]
b = model.linear.bias.data.cpu().numpy()[0]
print("m(slope)=", m, "n(y-intercept)=", b)
predictions_gpu = get_prediction(model, device_gpu, inputs)
But the results are so different not sure why left one CPU right one GPU. CPU training looks fine.
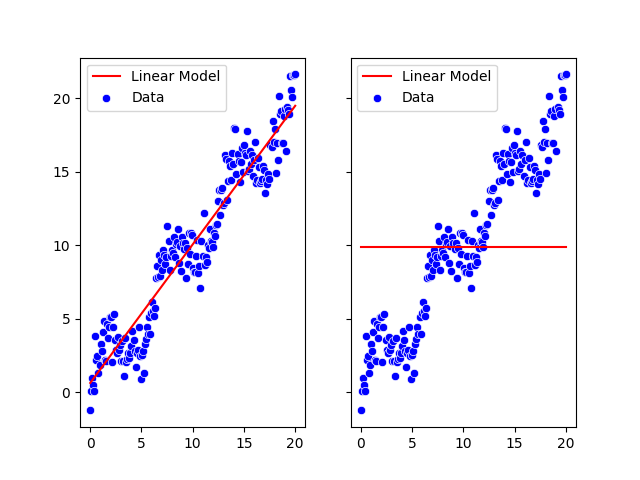
Does any one see some mistake in the process. Thanks in advance.