I’ve launched multiple training on the same machine, same environment, same data.
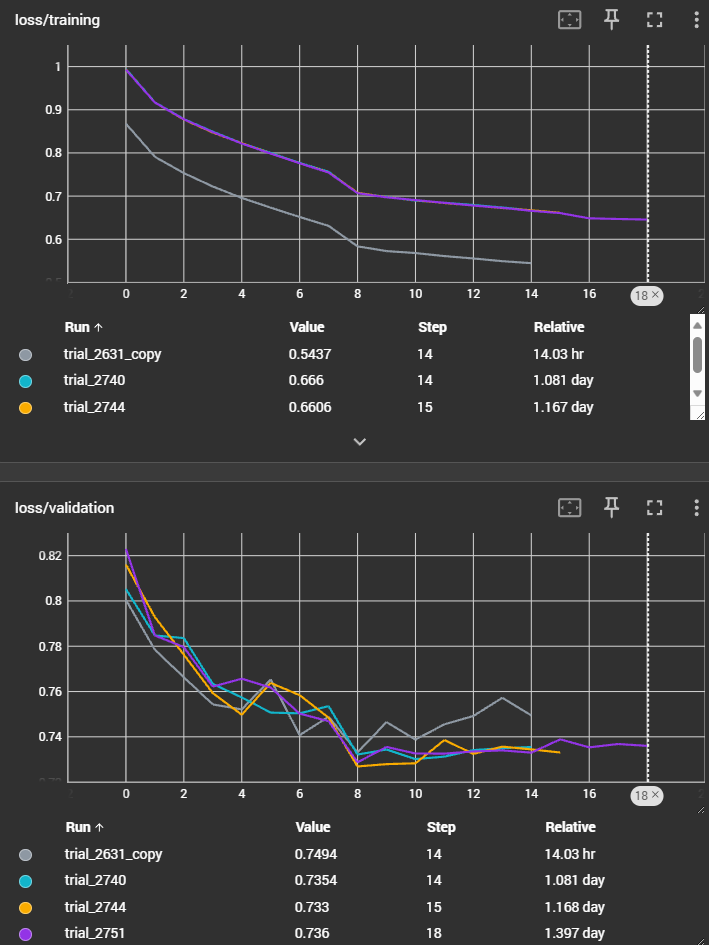
As you can see on the image below, i get similar losses (and similar accuracies, not shown here) for the training set across the different runs (the green, yellow and purple lines are so similar that they are stacked on the training loss plot). The grey line represent another configuration, so it’s ok that it’s different.
You can see however in the image below that the validation loss varies.
I’ve the following lines for the validation step:
if training:
dp = dp.shuffle(buffer_size=shuffle_buffer_size)
Imagine we’re searching for the lowest point on a randomized 2d terrain map. But we can only see our present slope. And each training run starts us at a different point on the map.
Now, imagine that instead of the map being 2 dimensions, it is 100 million dimensions (assuming 100m parameters). The loss function mapped over epochs or batches only tells you the altitude (or loss) that the model traveled during that run.
Thank for the answer J,
I use a pre-trained model to initialize the weights.
I see your explanation as helping to understand why different loss trajectory would be different from one training to another training in particular.
My question here is specifically on the example shown where the training loss trajectory is very similar but not the validation loss trajectory.
Anyway, in addition to the previous information, I should underline that the y-axis scale are different on the two tensorboard plot. The actual values differ from ~0.001 in for the training loss and ~0.01 for the validation loss.
Note that I’m not caring about reproducibility settings as here my question is related on this difference between the training loss variation and the validation loss variation, and not on the fact that a variation exist.
Do the models use dropout layers? These provide random masks on layer outputs during training.
The validation loss is a reflection of how the model is doing after that training epoch. And it looks to me like you begin overfitting after epoch 8 in most cases.
I’m not clear why you believe the validation loss should not have this kind of variation or what you are expecting.
Yes, I use dropout, but as i understand, that specifically could lead to more variation in the training loss and less in the validation loss.
I do the early-stoppint on another metric than the loss, so sometimes the training continue altough the loss starts to raise (anyway, it should continue as their is some patience before the early stopping).
I would expect curves for the validation loss that are closer to each other, like the above graph. And closer by reference-scale to the grey curve, that is another run based on another configuration.