Hi,
So I am trying to sanity-check my binary image classification model.
I am training it to overfit on 20 samples, now theoretically training loss should decrease and validation loss should increase. Because the model should not be learning anything but both my train & val loss are decreasing here
Validation accuracy is also following a non-random pattern,
Is my assertion for performance expectation true on overfitting on 20 samples and there is something wrong with my training loop/data loading process?
How can I triage it further?
Below are my metric graphs for the experiment -
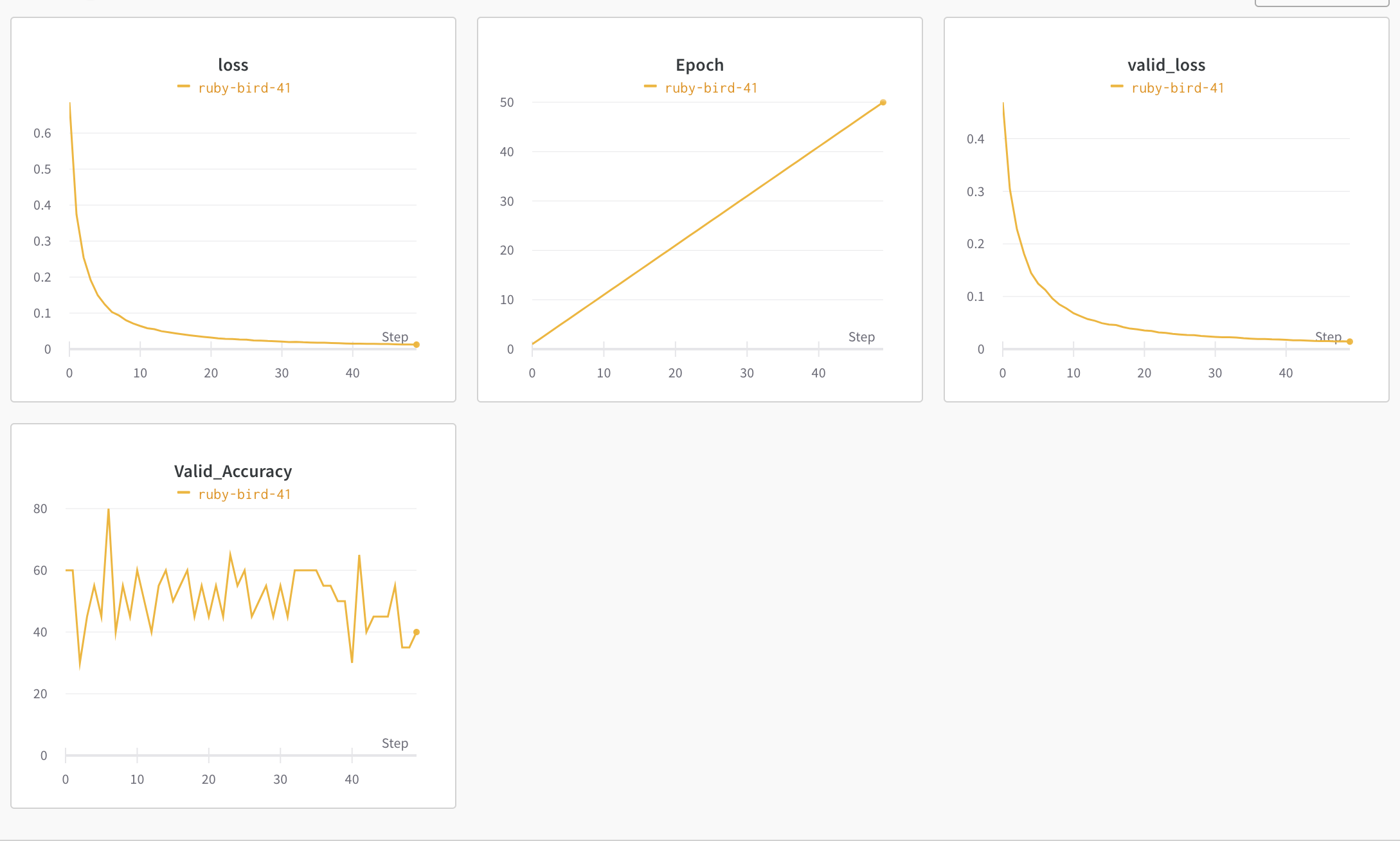
Hi Mr. Bing!
Your results do look fishy. In particular, your validation accuracy is roughly
50%, which usually means that your predictions are essentially random
guesses for binary classification, even though your validation loss is going
down to what appears to be a low level.
Could you show us your loss criterion (which I expect and would hope is
BCEWithLogitsLoss), how you compute your accuracy, and a training
accuracy graph to compare with your validation accuracy?
Is your training data balanced? That is, roughly what fraction of your
training and validation samples are positive? Could you give us the
true-positive / false-positive / true-negative / false-negative breakdown
of your training and validation predictions?
Best.
K. Frank
1 Like
Hi K. Frank,
My loss & optimizer looks like the below -
optimizer = torch.optim.SGD(model_transfer.parameters(), lr=config.lr)
optimizer.zero_grad()
criterion_transfer = nn.BCEWithLogitsLoss()
I don’t calculate accuracy generally on training data, should I be calculating it?
Nevertheless, I calculated it for this discussion-
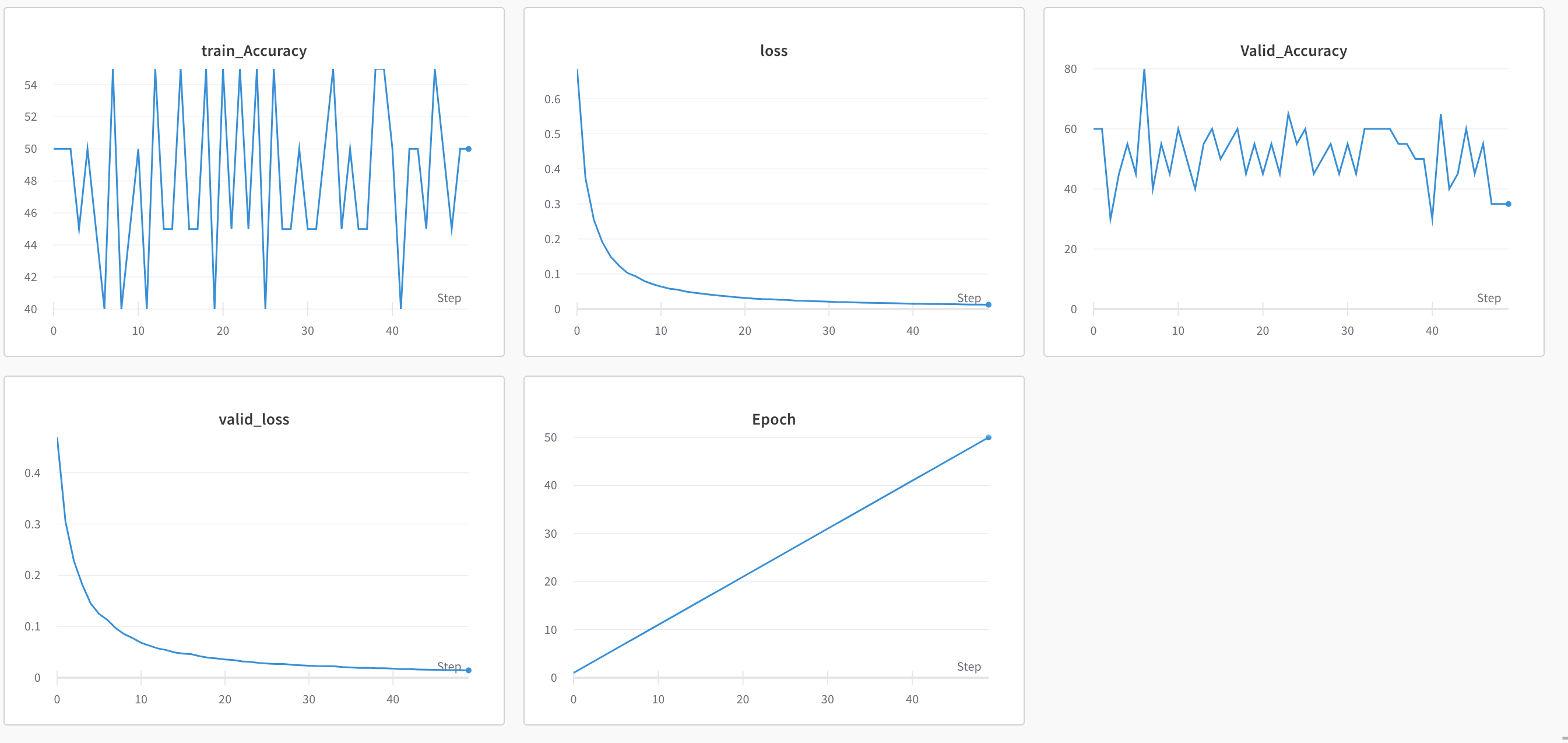
Data is not balanced. Also, I am just testing it on 20 samples so that I could figure out any potential issues in my training loop
I am calculating accuracy in a below way -
for batch_idx, (data, target) in enumerate(loader['train']):
preds = torch.max(output, dim=1, keepdim=True)[1]
train_total += data.size(0)
train_correct += np.sum(np.squeeze(preds.eq(target.data.view_as(pred)).cpu().numpy()))
train_accuracy = 100. * (train_correct/train_total)
and Val Accuracy in a similar way.
Below is the link for log with tp, tn, fp, fn values, I am sorry if it is not much readable, I’ll make it more human readable if you want-
Hi Mr. Bing!
This shows that both your training and validation accuracies fluctuate
around 50% while both your training and validation losses become
rather low. I don’t think (in normal usage) that you can get a loss that
low with BCEWithLogitsLoss when your accuracy is 50%. So I think
that you’re doing something fishy.
This looks very odd. When using BCEWithLogitsLoss for binary
classification, the output of your network would have a single value
(a logit) for each thing (e.g., batch element) you were making a
prediction for. In such a case you would not compute the argmax()
(max()[1]) of the output of your network to get any sort of useful
predictions.
What is the shape of output and what are its values supposed to mean?
You say that you are working with 20 samples. Could you post the output
of your network (after training) for those 20 samples, together with the
ground truth?
I didn’t follow the link to your “tp, tn, fp, fn.” They’re only four numbers.
You could just post them.
Best.
K. Frank
1 Like
Hi K. Frank,
Below is the shape of output for batch size-1-
Output Shape- torch.Size([1, 2])
Output- tensor([[0.2294, 0.6553]], device='cuda:0', grad_fn=<GatherBackward>)
Target Shape- torch.Size([1])
Target- tensor([0], device='cuda:0')
true_positives 0.0
false_negatives 1.0
true_negatives 0.0
false_negative 0.0
Also, adding the training loop, I am using Timm
import timm
model_transfer = timm.create_model('convnext_tiny_in22k', pretrained=True,num_classes=2)
and here is the output for batch size 20 for 20 samples only for 1 epoch-
Output- tensor([[ 0.2294, 0.6553],
[-0.0444, -0.0695],
[ 0.1748, 0.3308],
[ 0.4883, 0.5134],
[ 0.1779, 0.2593],
[-0.0736, 0.2526],
[ 0.7483, 0.4661],
[-0.2667, 0.4035],
[ 0.0905, 0.0604],
[ 0.2678, -0.2460],
[ 0.3801, 0.1053],
[ 0.2109, 0.3041],
[ 0.2760, 0.2031],
[ 0.1168, 0.5727],
[ 0.1044, 0.0052],
[ 0.2459, -0.1016],
[ 0.1527, 0.1206],
[-0.0633, -0.0126],
[ 0.1624, -0.0535],
[ 0.0871, 0.1854]], device='cuda:0', grad_fn=<GatherBackward>)
Target- tensor([[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0]], device='cuda:0')
Epoch: 1 Training Loss: 0.855001 Validation Loss: 0.877783 Training Accuracy: 50.000000 Validation Accuracy: 80.000000 Train_True Positive- 0.0 Train_False Positive- 200.0 Train_True Negative - 200.0 Train_False Negative - 0.0 Val_True Positive- 0.0 Val_False Positive- 4.0 Val_True Negative - 16.0 Val_False Negative - 0.0
Validation loss decreased (inf --> 0.877783). Saving model ..
Hi Mr. Bing!
I see problem with your data and results.
First I assume that “false-negatives 1.0” is a typo and should be
“false-positives 1.0” This means that this single sample (batch
size of 1) is a negative sample, incorrectly classified as positive.
If I understand this correctly, it means that 10 of the 20 samples are
predicted to be positive – that is the second of the two numbers is
algebraically larger than the first.
This says that all 20 of your samples are labelled as being negative.
Here you have 400 results, which I speculate is 20 times 20, but who knows?
But in any event both “False Positive” and “True Negative” mean a label of
negative. So all of your samples are negative samples (with half being
incorrectly classified as positive, just as in your set of 20 samples, above.
For your validation results, again all of your samples have ground-truth
labels of negative (this time with a quarter of them being incorrectly classified
as positive).
Two conclusions:
All of the samples you’ve showed are negative. That’s not only an unbalanced
data set, but fully useless.
I’m surprised that your model isn’t learning to always (or almost always)
predict negative, so your doing something wrong in your training. (If you
run a single batch of 20 through your model once and perform a single
backpropagation / optimization step, your model likely won’t learn much
of anything, including not learning to always predict negative.)
Best.
K. Frank
1 Like
Hi K. Frank,
I was really high on caffeine, I am sorry I calculated my confusion matrix values incorrectly.
Below are my metric for 2 samples of batch size 1 for 1 epoch.
Also, I am not getting your point of model learning to calculate negative values, none of my target values is negative so isn’t what the actual model is calculating right now should be judged on the basis of closest to the actual value.
Output-
tensor([[-0.0642, -0.0855]], grad_fn=<AddmmBackward0>)
Target-
tensor([0])
Pred-
tensor([[-0.0642]], grad_fn=<MaxBackward0>)
Output-
tensor([[ 0.1499, -0.2758]], grad_fn=<AddmmBackward0>)
Target-
tensor([0])
Pred-
tensor([[0.1499]], grad_fn=<MaxBackward0>)
Epoch: 1 Training Loss: 0.884152 Validation Loss: 0.716224 Validation Accuracy: 100.000000 True Positive: 0 false Positive: 0 true negative: 1 false negative: 0
Validation loss decreased (inf --> 0.716224). Saving model ...