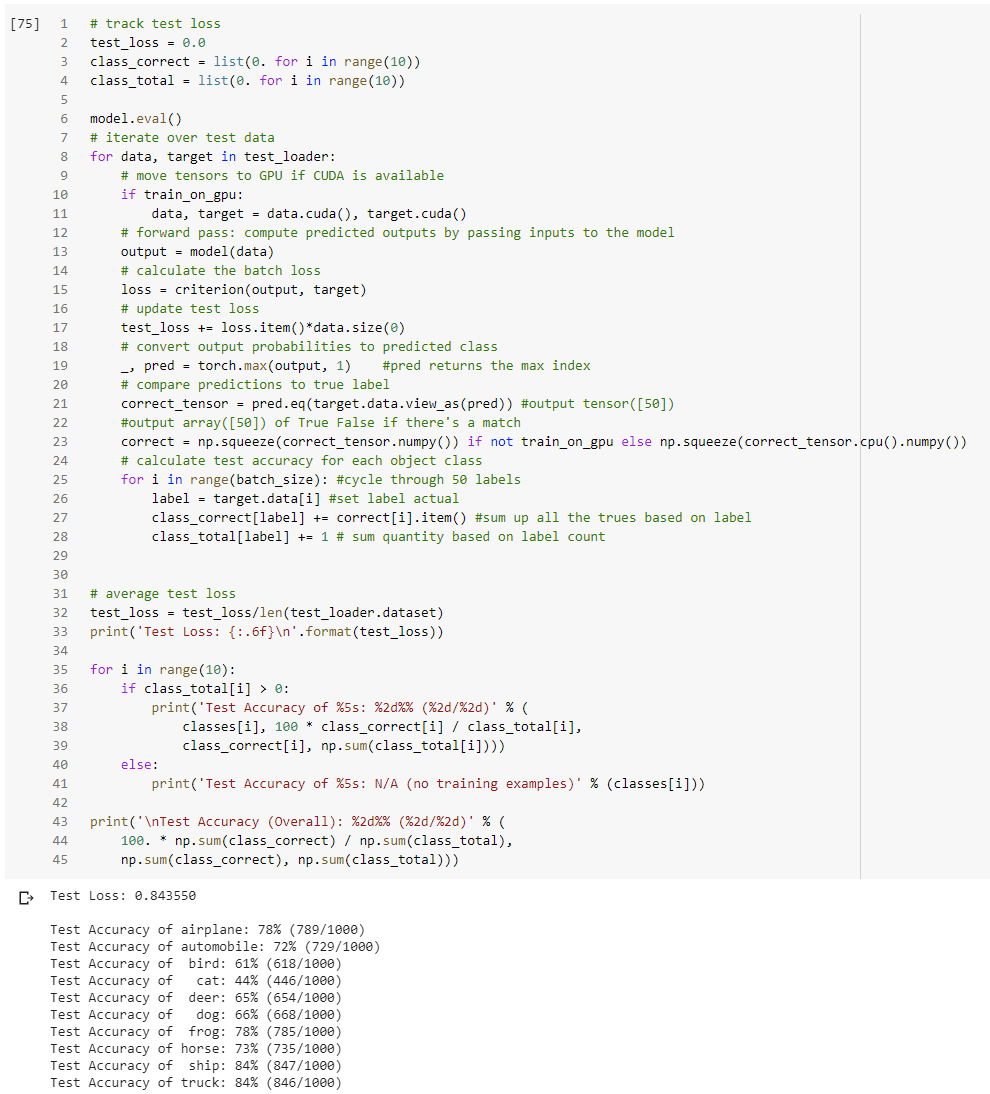
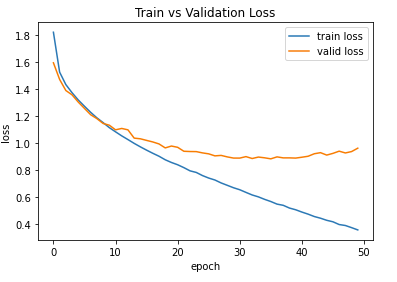
I train the CNN using the following
50 epoch
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
30 epoch
optimizer = optim.SGD(model.parameters(), lr=0.01)
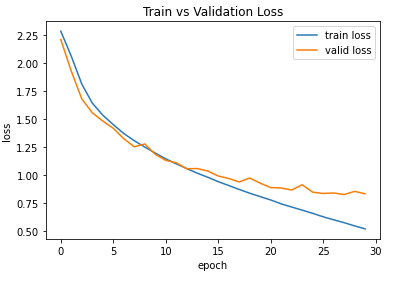
with reference to SGD,
I understand that train will always appear better than valid loss. So I guess this is normal.
Epoch is 30. Using colab to train like 50 and I think it will improve.
I understand that Adam should be better than SGD but the chart is quite bad , the valid seems to have a U shape.
- With reference to line 21, I understand the
.eq function but I don’t understand why we need to use target.data
pred.eq(target.data.view_as(pred)) . I think target without data should work too .
- At the start, we check for GPU else CPU
I understand when we train, we will invoke data.cuda() and target.cuda(). So when we do this we shift the tensor to GPU so that we harness the GPU right? Why do we still use GPU in validation and test since it’s just for inferencing? How does this link(if any) to model.train() and model.eval() ? Thanks a lot.

Note that the scaling of the y-axis is different and both validation losses seem to be around ~1.
I’m not sure, if the validation loss continues to decrease for SGD, but if so, you could stick to it.
Note that Adam is not universally better than SGD and you can achieve a better performance using SGD with careful tuning.
You don’t need to use the .data attribute and you should avoid using it, as it can have unwanted side effects.
Yes, that’s correct. The same applies to model.cuda() or model.to('cuda'), which transfers the parameters and buffers to the device.
The GPU can also be used for inference, which might also yield a speedup compared to a CPU run.
model.train() and model.eval() set the model and all submodules to training or evaluation mode.
These modes change the behavior of some modules such as dropout and batchnorm.
While dropout will be disabled during evaluation, batchnorm will use its running estimates for the mean and std instead of the current batch statistics. This is especially useful, if you are planning on using the model for inference with a single sample, as the “batch” statistics (for the single sample) might be noisy or not even computable.
-
I thought Adam is like ReLU, like a defacto standard. OK I will take note that we should consider SGD too.
-
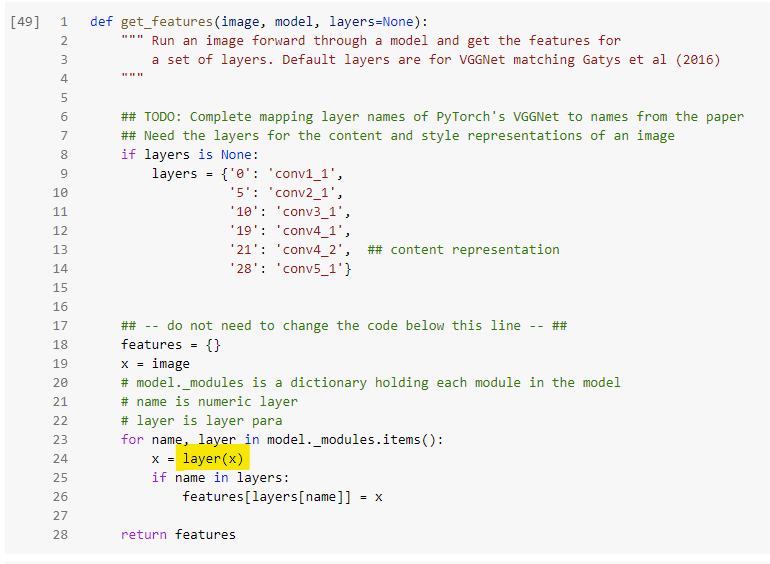
I’m doing some style transfer using VGG. More info if you need to see the full codes.
I understand when we do vgg._modules.items(). we will be able to extract layer number ( key) and layer parameters( values - i.e Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) )
What I do not understand why do we
layer(image) whereby image is the a tensor ( 1batch x channel x W x H).
I try to throw in a tensor but there is an error hence I was not able to reverse engineer what this function is trying to do.
- I’m not sure how to learn Deep Learning for CV for myself but it seems like style transfer is totally different from the multiclass classification that I’ve studied. So how does one learn after the CNN stage? Out of my head I can think of there is also ‘object detection like YOLO’ which I think there are functions that are entirely different too. Is it once you know object detection or style transfer you will use back similar codes?
(example if you know house price prediction using linear regression you will know how to other predictions? )
Maybe can share on a high level on how to learn?
Thanks.