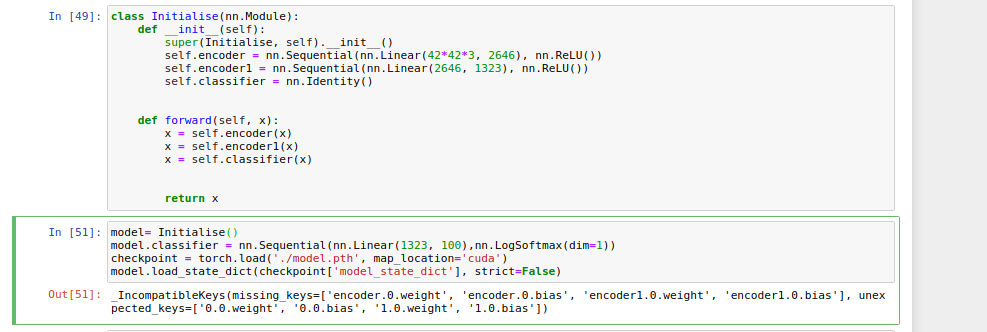
I’m trying to train Autoencoder as image classifier. Here is my code for Autoencoder
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# encoder
self.encoder = nn.Sequential(nn.Linear(in_features=784, out_features=16),
nn.ReLU()
)
# decoder
self.decoder = nn.Sequential(nn.Linear(in_features=16, out_features=784),
nn.ReLU(),
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
net = Autoencoder()
After training of Autoencoder I’m training classifier
# copy encoder part
new_classifier = nn.Sequential(*list(net.children())[:-1])
net = new_classifier
# add FC and Softmax
net.add_module('classifier', nn.Sequential(nn.Linear(100, x),nn.LogSoftmax(dim=1)))
Now I would like to Save and Load model in the below format.
torch.save(the_model.state_dict(), PATH)
Then later:
the_model = TheModelClass(*args, **kwargs)
the_model.load_state_dict(torch.load(PATH))
How can I load the model as above if I have 2 parts(Encoder and Classifier) ?
It is little bit confusing in Multi models save and load in documentation. It would be helpful if someone helps me with this.
Thanks