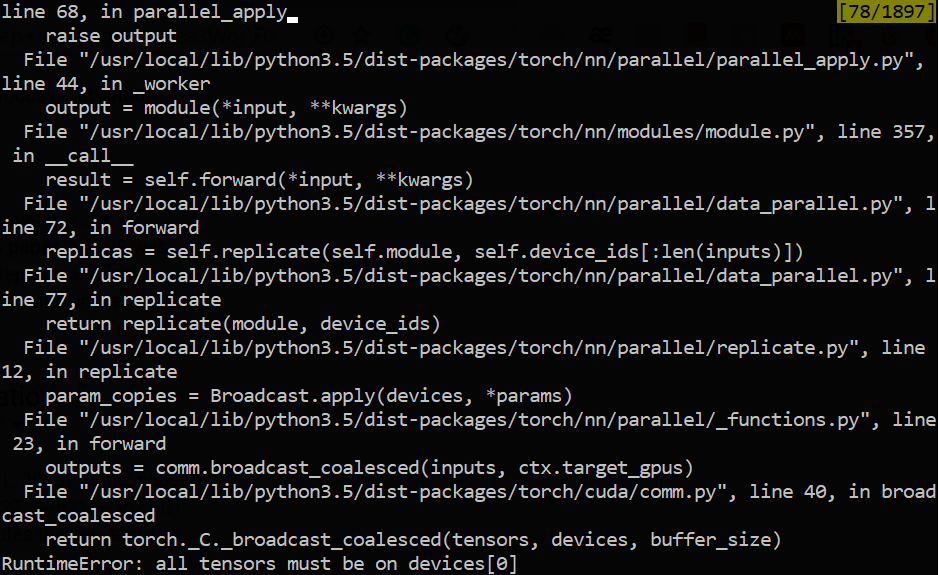
I was trying to resume the training of a model on multiple GPUs but I got this error
This is how I save the model during training. Any thoughts on how I can solve this?
Also, I know that saving the state_dict is the preferred way of saving models. But in my case, I optimize the layers of a network module on the fly so is there a way to save the modified module itself as well? Thanks.