If your optimizer has internal parameters, e.g. Adam, then yes, you should also store it.
I’m forking the official word level language modelling. I can’t find an explicit optimizer here. All I’ve is a loss.backward(). I’m not able to reproduce the results by saving the model like explained here.
In this tutorial the weight updates are performed manually in this line of code.
Since you don’t have internal estimates you don’t have to store anything regarding the optimization.
I saved the model which performed the following graph.
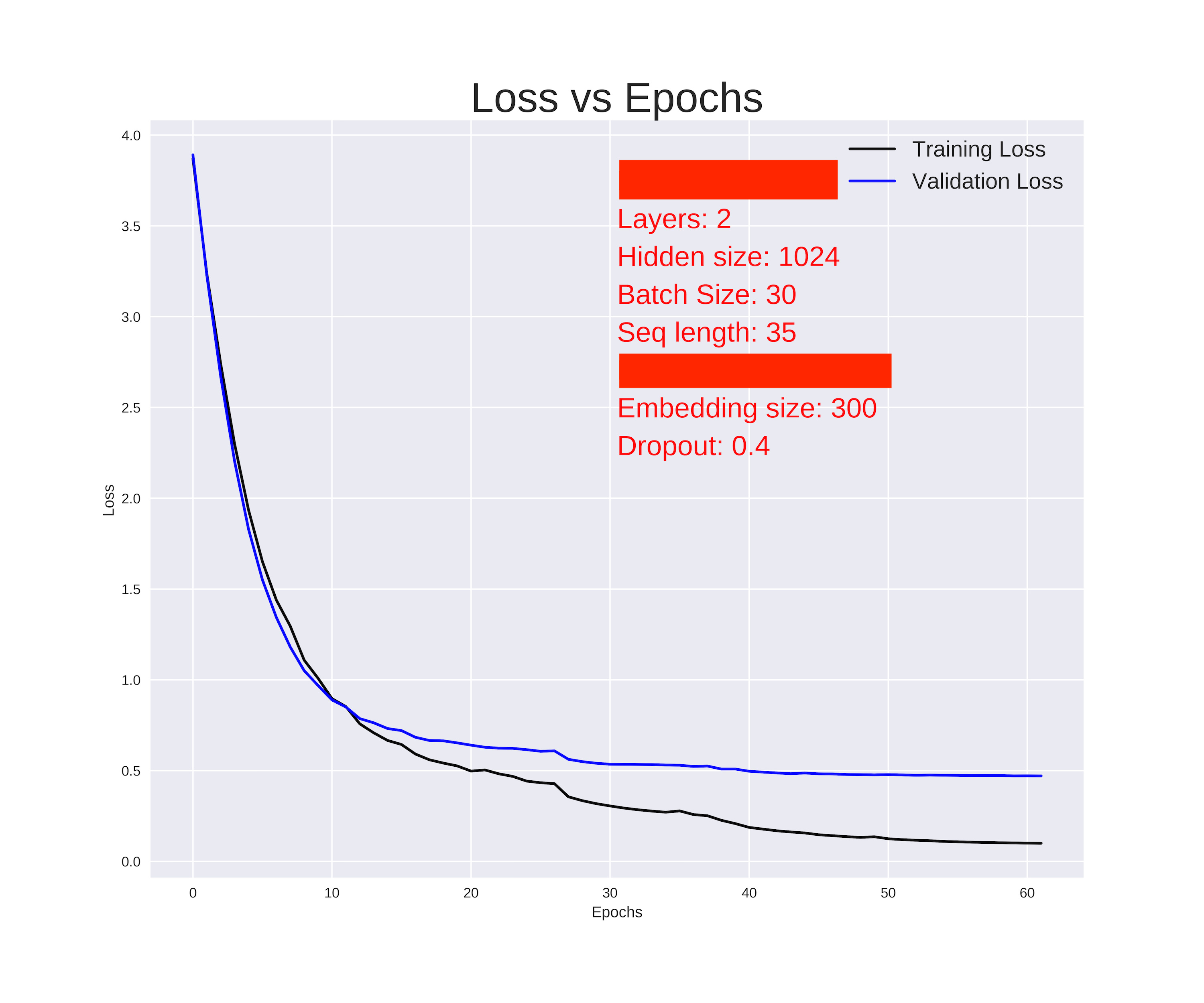
On reproducing the results with the model saved, my test error is,
End of training | test loss 17.28 | test ppl 32104905.14
Generated result is gibberish.
Something is terribly wrong. I’m not sure where I should check ![]()
Something looks fishy. Could you create a new thread and post your complete issue there?
It would also be easier to debug, if you could post your code so that we can have a look.
1 Like
I started a new thread at here.
Hi! I have a problem with loading my model. I’m training VGG19 on cifar10 in colab, when I load it in colab it is OK but when I load it on my laptop with same code it gives error. They’re both python3 and trained with cuda.
Error:

Save code
def save_checkpoint(state, filename):
torch.save({'state_dict': net.state_dict(),
'optimizer': optimizer.state_dict(),
}, filename)
Load
checkpoint = torch.load('./vgg19_200.pth')
net.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
1 Like
hello I’m trying to save my adam optimizer,
but why whenever I load it, the state_dict is always different
if I restart my environment?
I’ve also make my own thread here, Saved model have higher loss
thank you
no such thing as mistake or understand or not, think any is ok
Is there a way to save and load models from s3 directly?
Have you solved this problem? I have encountered this problem, I don’t know where it is wrong.
Yes, if you use StringIO you can create a file stream, write your model state to it, then push that to s3.
What I additionally do is use joblib to add compression and pickle after writing to the stream, push that to s3, then unload with joblib back to a file stream object and read the model state back into a model object to resume.
It’s not necessary, you can use .copy() it’ll work fine too. 
He just mean when you need to evaluate or infer.
Hi, I am new to pytorch and was wondering how to create the model class for a trained pytorch model. I wish to use that to save and load the model for serving it with flask.
MyModel.eval() insert before or after state_dict method ? i think is after,beacuse after load parameters and freeze some parameters,right ?
Yes, you are right! Put MyModel.eval() after loading state_dict.
Hi,
So a sort of related question but in the context of the saving the optimizer. Is saving/loading the full optimizer object, the same as saving/loading only the optimizer’s state_dict() when resuming training? Aside from the obvious that saving only the state_dict(), saves memory…
In my case, the results are correct without eval() but not with it.
I am trained Gener. Adv. Net.
Wow. I did not think of that, but this also worked for me and I have no idea why.