I wish to add to a Tensor at specified indices. This can be achieved in PyTorch, with the Tensor reshaped to 1D for simplicity, using simple indexing (u[x] += v) or with u.scatter_add_(0, x, v). The former is slow, but in eager mode the latter provides performance almost equivalent to C. However, if I use torch.compile, scatter_add_ becomes substantially slower, especially when the number of additions is small. I am currently running on a CPU, using PyTorch 2.5.1.
Here is a demonstration:
scatter_add.c:
#include <stdint.h>
void scatter_add(float *restrict const u, float const *restrict const v,
int64_t const *restrict const x, int64_t n) {
for (int64_t i = 0; i < n; ++i) u[x[i]] += v[i];
}
Compile with gcc -O2 -march=native -fPIC -shared scatter_add.c -o scatter_add.so
Python code to implement Python approaches and run timing:
import torch
import timeit
from ctypes import CDLL, c_void_p, c_int64
dll = CDLL('./scatter_add.so')
dll.scatter_add.restype = None
dll.scatter_add.argtypes = [c_void_p, c_void_p, c_void_p, c_int64]
def scatter_add1(u, v, x):
u[x] += v
def scatter_add2(u, v, x):
u.scatter_add_(0, x, v)
number = 1000
repeat = 10
times = [] # 2d array of runtimes: [p, implementation index]
for ns in [10**p for p in range(6)]: # ns = number of adds
u0 = torch.randn(100000) # Tensor to add to
x = torch.randperm(len(u0))[:ns] # indexes to add to
v = torch.randn(ns) # values to add
ns_times = [] # timings for this "ns": [implementation index]
# C implementation
u = u0.clone() # Clone u0 so same for all implementations
ns_times.append(
min(
timeit.repeat(lambda: dll.scatter_add(u.data_ptr(), v.data_ptr(),
x.data_ptr(), ns),
number=number,
repeat=repeat)))
# Py1 implementation (scatter_add1)
u = u0.clone()
ns_times.append(
min(
timeit.repeat(lambda: scatter_add1(u, v, x),
number=number,
repeat=repeat)))
# Py2 implementation (scatter_add2)
u = u0.clone()
ns_times.append(
min(
timeit.repeat(lambda: scatter_add2(u, v, x),
number=number,
repeat=repeat)))
# compiled Py1
scatter_add1c = torch.compile(scatter_add1)
u = u0.clone()
ns_times.append(
min(
timeit.repeat(lambda: scatter_add1c(u, v, x),
number=number,
repeat=repeat)))
# compiled Py2
scatter_add2c = torch.compile(scatter_add2)
u = u0.clone()
ns_times.append(
min(
timeit.repeat(lambda: scatter_add2c(u, v, x),
number=number,
repeat=repeat)))
times.append(ns_times)
Plot results:
import matplotlib.pyplot as plt
timeslog10 = torch.tensor(times).log10().numpy()
plt.plot(timeslog10,
label=['C', 'Py 1', 'Py 2', 'Py 1 compiled', 'Py 2 compiled'])
plt.legend()
plt.ylabel('Runtime (log10)')
plt.xlabel('Number of adds (log10)')
plt.savefig('runtimes.png')
plt.show()
Result:
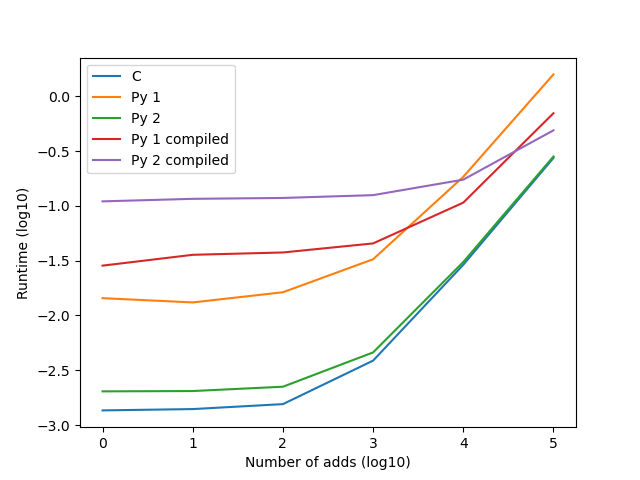
Notice that “Py 2” (green line, using scatter_add_) has almost the same performance as C in eager mode, but when compiled (purple line) is substantially slower.
Is there any way to improve the performance? I can guarantee that the indices are all unique, so atomic adds are not needed. I can also guarantee that the indices are all within bounds.