Hi, I have a question about the significant performance boost on scatter_reduce ops since the version of pytorch 2.2.
I used to develop on torch2.0, and I observe significant performance decay when unique value count in my index tensor is very low, that is, for example, 10M elements been scattered and reduced into a small amount of groups (for example 10 groups).
I post a question before. scatter-and-reducing 10M elements into 10 group will cost me up to 95.84s!
Experiemnt :
I conduct a experiment to compare the performance of scatter reduce in pytorch2.0 and pytorch2.2 respectively.
device :Nvidia 3090
code: we test the performance difference under different group_number, that is the unique value count in the index tensor.
test_scale: we set the length of the tensor as 10M, and the group number is 10M, 1M ,100K, 10K, 1K…
test distribution: I also test whether the distribution of the element in the index will influence the performance.
In each group number, I test the consecutive distribution, that is all identical element in the index tensor are placed consecutively like [0,0,0…,1,1,1…,n,n,n…],versus random distribution that the index tensor and the source tensor are shuffled by randomly generated permute index.
import torch
import time
scale = int(1e7)
group_num = scale
data = torch.randint(0,10,size=((scale),),device= 'cuda',dtype = torch.int64)
permute_idx = torch.randperm(scale,device = 'cuda')
while group_num >=10:
# generate idx
repeat_num = int(scale/group_num)
# ordered idx like [0,0,0...,1,1,1....,n,n,n....], identical element are placed consecutively
ordered_idx = torch.arange(group_num,device = 'cuda').view(-1,1).repeat(1,repeat_num).view(-1)
# shuffle ordered idx and data according to permute_idx
rand_idx = ordered_idx[permute_idx]
rand_data = data[permute_idx]
# test performance on rand data
# test for 10 round
res_list = []
for i in range(10):
res = torch.zeros(group_num,device= 'cuda',dtype=data.dtype)
start = time.time()
res.scatter_reduce_(src = rand_data,index = rand_idx, dim = 0,reduce = 'amin')
torch.cuda.synchronize()
end = time.time()
res_list.append(end-start)
#use the average time of the last 3 round as the result
val1 = sum(res_list[-3:])/3
print(val1)
# print(res)
#=======================test for consecutive(ordered) version
res_list = []
# test performance on rand data
# test for 10 round
for i in range(10):
res = torch.zeros(group_num,device= 'cuda',dtype=data.dtype)
start = time.time()
res.scatter_reduce_(src = data,index = ordered_idx, dim = 0,reduce = 'amin')
torch.cuda.synchronize()
end = time.time()
res_list.append(end-start)
# use the average time of the last 3 round as the result
val2 = sum(res_list[-3:])/3
print(val2)
# print(res)
print(f'========{group_num}==========')
group_num = int(group_num/10)
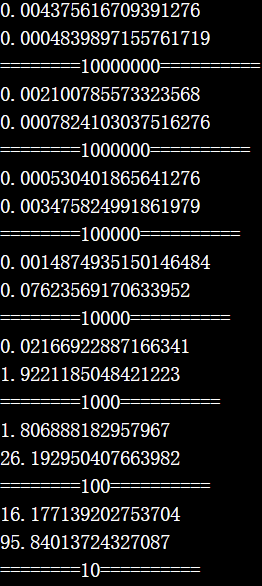
Test result
torch 2,0:
torch2.2:

We can observe significant performance difference between the execution of the same code indifferent pytorch version.
observations in In torch2.0:
- the performance of scatter_reduce is reduced according with the decrease of group number
- and the consecutive version(lower) suffered from more severe performance drop than the random version(upper).
- When the group number equals 10, random version in torch2.0 will cost 16s and consecutive version will cost 96s!.
Pytorch use atomic ops to implement scatter reduce operations. Therefore I tried to use memory contention to explain this observation since we are updating the shared memory under large parallelism scenario, when the group number is low, there might exists high risk that thousands of threads competing the access right of a particular element thereby causing a sharp performance degrade. And the worse performance of consecutive version can support my explaination .
observations in In torch2.2:
However the observation above in torch2.0 disappeared in torch2.2. They can run perfectly efficient on low group number scenarios.
So I am wondering what is the main optimization pytorch did to overcome this problem. And what strategy did the new version applied to get rid of the memory contention problem!