I tried to add a scheduler to my network for better convergence but I get worse results
without any schedulers:
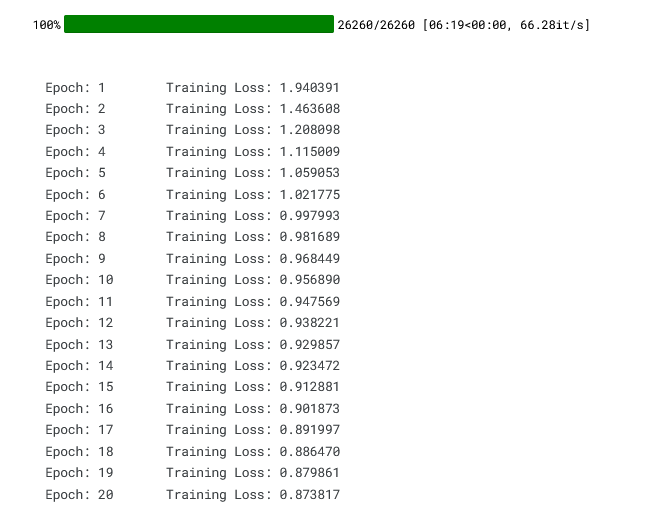
with schedulers on the same network:
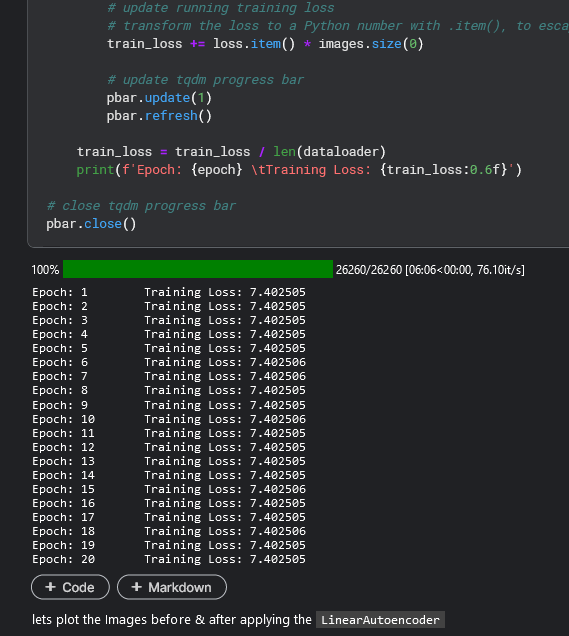
all code: Denoising Autoencoders (DAE) in PT & PT⚡ | Kaggle
what is my mistake?
I tried to add a scheduler to my network for better convergence but I get worse results
without any schedulers:
with schedulers on the same network:
all code: Denoising Autoencoders (DAE) in PT & PT⚡ | Kaggle
what is my mistake?
Are you calling scheduler.step()? (In case there is a learning rate warmup and the learning rate is never changed from the initial value)
yes, I do as I see in the documentation :
# tqdm progress bar
pbar = tqdm(total=epochs * len(dataloader), file=sys.stdout, colour='green')
model.train()
for epoch in range(1, epochs+1):
# monitor training loss
train_loss = 0.0
# Loops over our dataset in the batches the data loader creates for us
for data in dataloader:
# Get the data
images, labels = data
# flatten images, keeps the three channels and merges all the remaining dimensions into one,
# figuring out the appropriate size.
images = images.view(images.size(0), -1)
# add noise to the images
noisy_images = images + 0.5 * torch.randn(*images.shape) # 0.5: noise_factor
noisy_images = np.clip(noisy_images, 0., 1.)
# place all the tensors on the same device
images, noisy_images = images.to(device), noisy_images.to(device)
# forward pass, Feeds a batch through our model
outputs = model(noisy_images)
# calculate the loss - measure how far (wrong) the noisy from the original image
loss = criterion(outputs, images)
# clear the gradients of all optimized variables from the last round
optimizer.zero_grad()
# backward pass, Propagate the loss signal backward
loss.backward()
# perform a single optimization step (update model parameters)
optimizer.step()
# Step the learning rate scheduler
scheduler.step(loss)
# update running training loss
# transform the loss to a Python number with .item(), to escape the gradients.
train_loss += loss.item() * images.size(0)
# update tqdm progress bar
pbar.update(1)
pbar.refresh()
train_loss = train_loss / len(dataloader)
print(f'Epoch: {epoch} \tTraining Loss: {train_loss:0.6f}')
# close tqdm progress bar
pbar.close()
Could you share how you are creating the scheduler (e.g., how the optimizer is being passed, etc.) and check if the state dict and learning rate of the optimizer (e.g., via .state_dict() and .get_lr() ) makes sense?
that’s how i instantiate the optimizer & scheduler:
lr = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5) # weight decay: L2 penalty
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5)
I found the problem: moving the line scheduler.step(loss) outside the inner loop after calculating train_loss. and passing in train_loss instead of loss to the scheduler’s step method.
My mistake ![]()