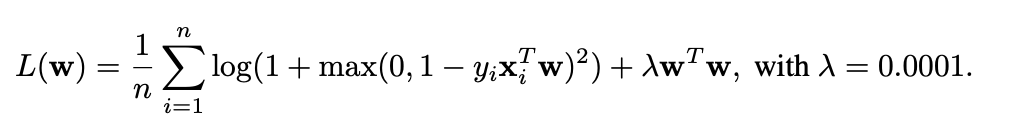My main question is how to calculate the second order derivatives of a loss function. But I started with a toy example as follows:
import torch
x = torch.tensor(1., requires_grad = True)
y = 2*x**3 + 5*x**2 + 8
y.backward(retain_graph=True, create_graph=True)
x.grad
y.backward()
x.grad
My thought is by call “backward()” twice would give me the second order derivatives, but the answer is 32 which is not correct. It would be really appreciate if someone can explain where is wrong.
And second my goal is to calculate the second order derivatives of the following loss function. I have this following defined loss function, and I tried to use newton’s method to do optimization. Since newton’s method requires the first derivative and second derivative at the each iteration, so I tried to write some code as follows:
If you have a single input and single output, you want to do the following:
(note that using .backward() for higher order derivatives is discouraged because the .grad field becomes hard to reason about).
first_derivative = autograd.grad(loss, x, create_graph=True)[0]
# We now have dloss/dx
second_derivative = autograd.grad(first_derivative, x)[0]
# This computes d/dx(dloss/dx) = d2loss/dx2
@albanD What should I do to take the second derivative of a 2D tensor (or list of 2D tensors)?
Specifically, I need to get the second derivative w.r.t. all parameters in the network.
Currently, I have set up the weights of the network as a ParameterDict weights and am doing the following: grads = torch.autograd.grad(criterion, weights.values(), create_graph=True
and now I want to again take the derivative w.r.t. weights.values() but this time of grads which is a list of 2D tensors rather than of the scalar criterion.
Do you want the full hessian matrix? If so, you will need to “reconstruct” it by doing multiple times the second backward pass with a grad_output that will be a one-hot matrix for each entry in the 2D Tensors one after the other.