I’m trying out second order differentiation using autograd, and the following example works:
import torch
x = torch.tensor(2.0, requires_grad=True)
# Define the function
y = (x ** 2)
# Compute the first derivative
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0]
# Compute the second derivative
d2y_dx2 = torch.autograd.grad(dy_dx, x, create_graph=True)[0]
print(d2y_dx2.item()) # Prints 12.0
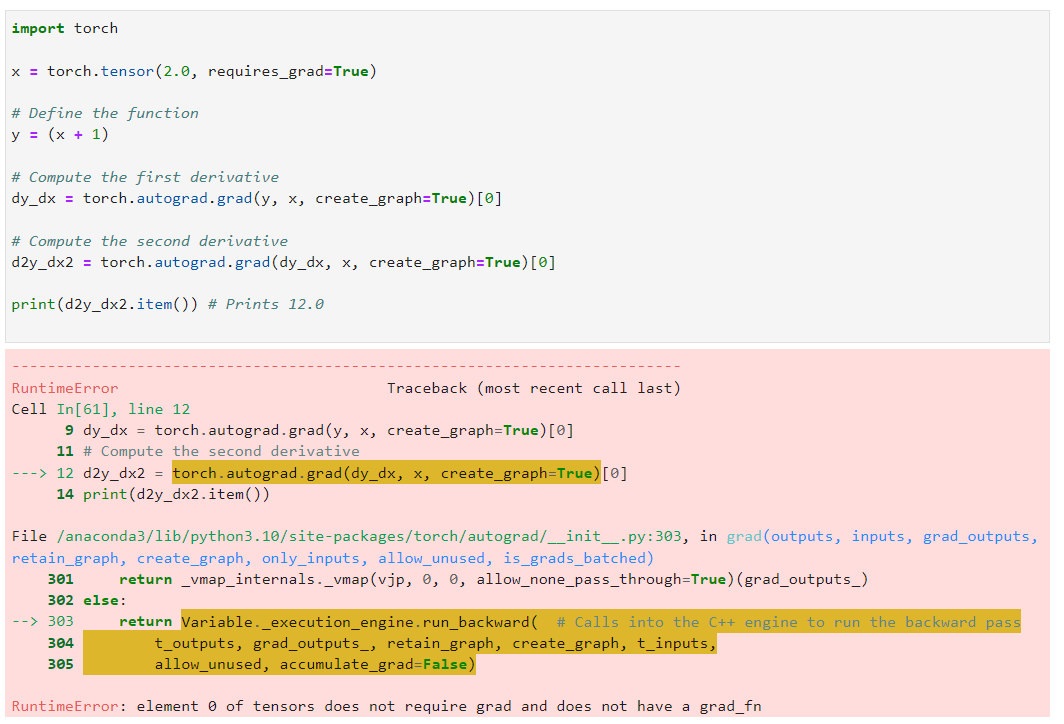
HOWEVER, when I simply change “(x ** 2)” to “(x + 1)”, it throws error:
I don’t understand why the second example doesn’t work if the first does, I was wondering if someone could explain this to me.
( Pytorch: 2.0.0 stable with working CUDA, Ubuntu 18, Anaconda, docker)
Thank you very much for your answer!
This behavior of autograd surprises me because I understand that the second order derivative of a linear function is always zero, however at the same time it does have a second order derivative. My concern is that if I write a generic function that uses the second derivative of its argument function, then I would prefer not to have to treat linear functions as a special case.
Is there a way to change this default behavior?
A “hack” I currently found is writing something like “(x ** 1) + 1” which it doesn’t complain about.
Now that I think more about it, could it be that autograd is intended to be mainly used for gradient descent and it’s designed this way because if a derivative is constant zero then it’s likely a bug in the model?
Hi @kgg
The function x+1 is linear, and the second order gradient of it is zero.
When such is the case, many of the times, autograd disconnects the computation graph. That to say, autograd is unable to differentiate whether, for a tensor, it’s the case of zero gradient (constant function) or no gradient (requires_grad=False or no graph). In your code:
import torch
x = torch.tensor(2.0, requires_grad=True)
# Define the function
y = (x+1)
# Compute the first derivative
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0]
print(dy_dx.requires_grad) # False
print(dy_dx.grad_fn) # None
# Compute the second derivative
d2y_dx2 = torch.autograd.grad(dy_dx, x, create_graph=True)[0] # error
That is expected. I point you to the docs to understand why. Specifically, you might benefit from digging into how the computation graph is actually constructed during tensor calculations. Feel free to ask any questions on this part.
Not sure! While trainings NNs, we usually do not require/use second order optimizations, so I am just guessing that this behaviour of autograd is intended to aggressively free as much memory as possible while the model trains. @ptrblck might help clarify this behaviour better.
Yes, I think this is expected behavior as explained here.
I.e. torch.autograd.grad expects to find x in the computation graph, which won’t be there since the output does not have any dependency on x anymore as it’s a constant.