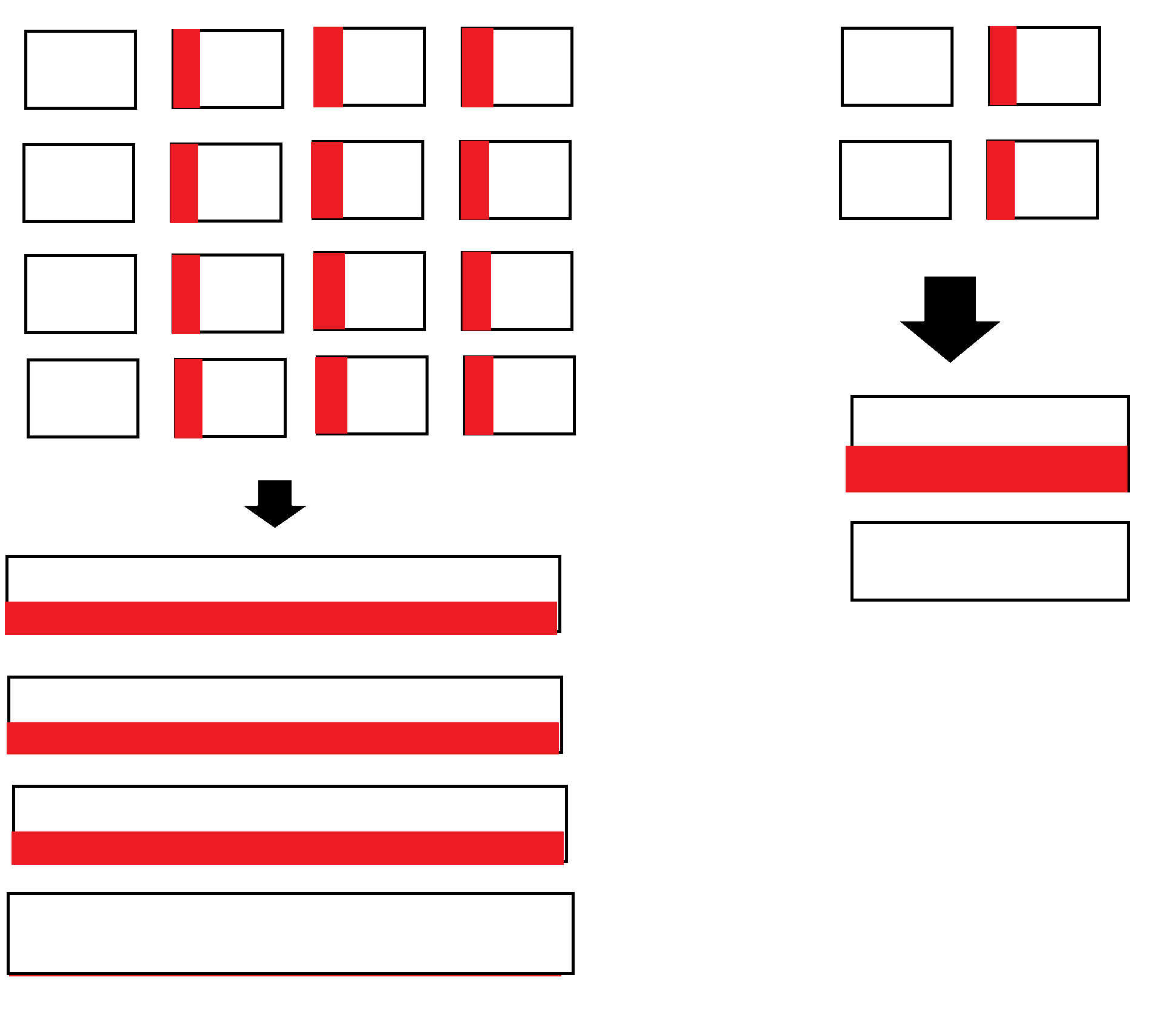
I’m looking to seamlessly blend tensors together. Currently the code below separates a tensor into overlapping tiles, and then it puts the tiles back together. If any of the tiles are slightly modified, the boundaries between them will become extremely obvious when they’re put back together, and thus the overlapping regions also can’t just be added together either.
import torch
from PIL import Image
import torchvision.transforms as transforms
def split_tensor(tensor, tile_size=256, overlap=0):
tiles = []
h, w = tensor.size(2), tensor.size(3)
for y in range(int(-(h // -tile_size))):
for x in range(int(-(w // -tile_size))):
y_val = max(min(tile_size*y+tile_size +overlap, h), 0)
x_val = max(min(tile_size*x+tile_size +overlap, w), 0)
ty = tile_size*y
tx = tile_size*x
if abs(tx - x_val) < tile_size:
tx = x_val-tile_size
if abs(ty - y_val) < tile_size:
ty = y_val-tile_size
tiles.append(tensor[:, :, ty:y_val, tx:x_val])
if tensor.is_cuda:
base_tensor = torch.zeros(tensor.squeeze(0).size(), device=tensor.get_device())
else:
base_tensor = torch.zeros(tensor.squeeze(0).size())
return tiles, base_tensor.unsqueeze(0)
def rebuild_tensor(tensor_list, base_tensor, tile_size=256, overlap=0):
num_tiles = 0
h, w = base_tensor.size(2), base_tensor.size(3)
for y in range(int(-(h // -tile_size))):
for x in range(int(-(w // -tile_size))):
y_val = max(min(tile_size*y+tile_size +overlap, h), 0)
x_val = max(min(tile_size*x+tile_size +overlap, w), 0)
ty = tile_size*y
tx = tile_size*x
if abs(tx - x_val) < tile_size:
tx = x_val-tile_size
if abs(ty - y_val) < tile_size:
ty = y_val-tile_size
base_tensor[:, :, ty:y_val, tx:x_val] = tensor_list[num_tiles] # Put tiles on base tensor made of zeros
num_tiles+=1
return base_tensor
# Load image and
test_image = 'test_image.jpg'
image_size=1024
Loader = transforms.Compose([transforms.Resize(image_size), transforms.ToTensor()])
input_tensor = Loader(Image.open(test_image).convert('RGB')).unsqueeze(0)
# Split image into overlapping tiles
tile_tensors, base_t = split_tensor(input_tensor, 512)
# Put tiles back together
output_tensor = rebuild_tensor(tile_tensors, base_t, 512)
# Save output to see result
Image2PIL = transforms.ToPILImage()
image = Image2PIL(output_tensor.cpu().squeeze(0)).save('output_image.png')