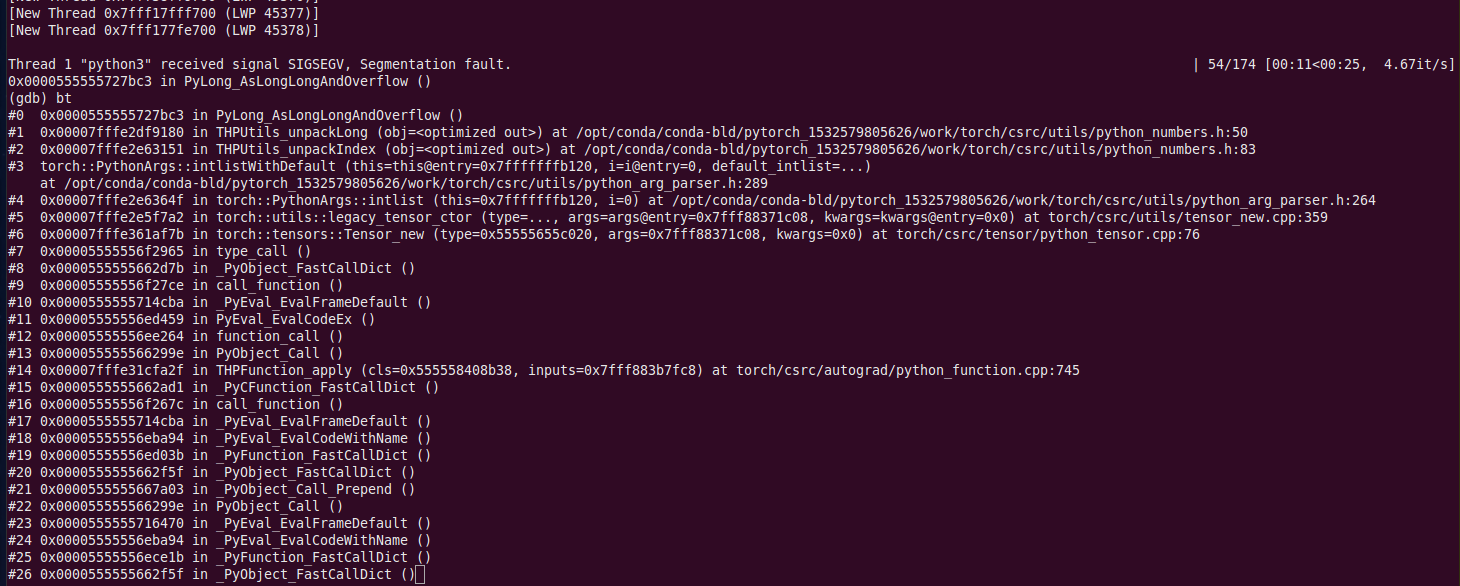
When I run training with a program for several epochs, it often raises a segmentation fault, and I use GDB to catch it and get the following information, bug I don’t know how to deal with it.
My pytorch version is 0.4.1, it seems like pytorch 0.4.0 doesn’t have this problem, but I am not sure.
Based on the error it seems you have an overflow creating a long long instance. Here is the description of this error.
I guess you are trying to create a LongTensor using some values? Do you see any chance of checking this value?
Note that the plain Python int type is unbounded in Python3, i.e. there are no max and min values.
I’m not sure, if this might be related, as the posted issue does not seem to have the same error.
It seems the linked issue is related to the build process.
Update:
I have located the original problem in my project, which occurs in this line:
temp = torch.cuda.IntTensor(B, N)
where B=1 is a python int type, N=1024 is np.int32 (such as got by numpy array A[0]).
The segmentation fault happened randomly and I cannot reproduce it by several line codes, which can be fixed by converting the second argument N to the standard int type of python.
My pytorch version is “1.0.0a0+76ab26c”.
Hope it helpful for the update of pytorch, and can you tell me what happens here?
Thanks very much.
So if you use a plain Python int, the code works fine, but crashes randomly if you pass a np.int32?
Also, this issue still occurs on the latest master build?
Did you make sure to run your code with CUDA_LAUNCH_BLOCKING=1 python script.py args?
Otherwise the stack trace might point to the wrong line of code, since CUDA calls are asynchronous.
Yes, my codes works fine for plain Python int and randomly crashes if pass N as np.int32.
I didn’t try the latest master build since my codes have some c extensions which are inconsistent with newest master and I still need time to convert them to newest pytorch. Currently my pytorch version is “1.0.0a0+76ab26c” .
Actually I didn’t run my codes with CUDA_LAUNCH_BLOCKING=1, but I think the segmentation fault occurs in temp = torch.cuda.IntTensor(B, N) since I use python faulthandler lib to locate it, which is consistent with the gdb results as before, and I have tried many times.