This is a repost from here, as I’m hoping someone in this forum might have some additional expertise in feature fusion.
Is it possible to perform feature fusion using a self-attention mechanism? I have data distributed over a graph, and multiple feature modalities sampled per node that I would like to “optimally” combine for a node classification problem. Let’s say that I have a graph $G=(V,E)$ with $N$ nodes. For each node, we sample $M$ different modalities, such that each node $v$ is characterized by $M$ feature vectors $\in \mathbb{R}^{m_{1}}, \mathbb{R}^{m_{2}}…\mathbb{R}^{m_{M}}$. For simplicity, assume $m_{1} = m_{2} = … = m_{M} = D$. I’m interested in “fusing” these features in a more intelligent way than simply concatenating them and passing them through a linear layer or MLP.
Assuming each node $v$ is characterzed by a feature matrix $x_{i} \in \mathbb{R}^{M \times D}$ (where $M$ is the number of modalities, and $D$ the input dimension), a transformer approach over modalities would yield something like this:
$$
\begin{align}
Q = x_{i}W_{q} \
K = x_{i}W_{k} \
V = x_{i}W_{v}
\end{align}
$$
where $W_{q,k,v} \in \mathbb{R}^{D \times p}. We then have that
$$
\begin{align}
Z = softmax(\frac{QK^{T}}{\sqrt{D}}, axis=1)V
\end{align}
$$
where $Z \in \mathbb{R}^{M \times D} and $Z_{i}$ is the fusion of modalities with respect to modality $i$ (I think – correct me if I’m wrong, please). I could then sum over the rows of $Z$ to compute the final combination. Does this seem correct? I havn’t found many papers on using self-attention for feature fusion, so any help is much appreciated.
So I used the link for the better maths rendering, but you have two different uses of the index i there: in the input, it is an index over the nodes, in the output, you use it as an index over the modality in your question. But in self-attention, one would typically expect the inputs and the outputs to match in shape, so if your inputs are N x M x D in your notation, so would your output be of the same.
That said, attention seems like a thing to try in a situation like yours. If you want to go to N x D outputs, there would seem to several options
pool over the features after the attention,
have a “node token” additional modality that works similar to the class token in BERT / vision transformers, in particular if you have several attention blocks stacked as in transformers,
go the “external attention” way of separating Q from KV and make Q independent of the modality, this would make your output independent of the modality. However, then the node must “know” which modalities to attend to.
I am afraid I cannot help you with the literature bit.
So to me, the defining bit for self-attention is that QKV all come from the same input.
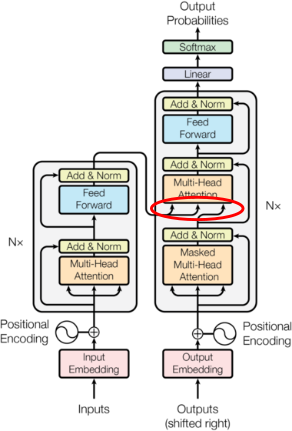
Using the image from the famous Vasvani et al: Attention is all you need paper: In the decoder, you have an attention where the Q comes from the decoder while KV is on the encoder (so the “decoder looks at the encoder” - the red circle):
But in your case it may be natural to take the Q just from the node, so the linear for Q takes N x D and the linear for KV take N X M x D. This may or may not work better than just pooling over the modalities after the attention layer.