So to me, the defining bit for self-attention is that QKV all come from the same input.
Using the image from the famous Vasvani et al: Attention is all you need paper: In the decoder, you have an attention where the Q comes from the decoder while KV is on the encoder (so the “decoder looks at the encoder” - the red circle):
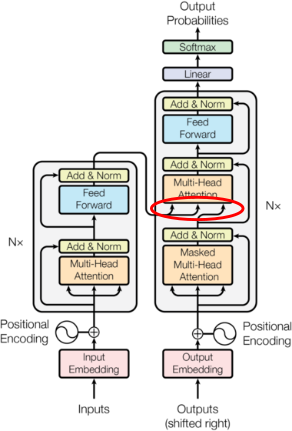
But in your case it may be natural to take the Q just from the node, so the linear for Q takes N x D and the linear for KV take N X M x D. This may or may not work better than just pooling over the modalities after the attention layer.
Best regards
Thomas