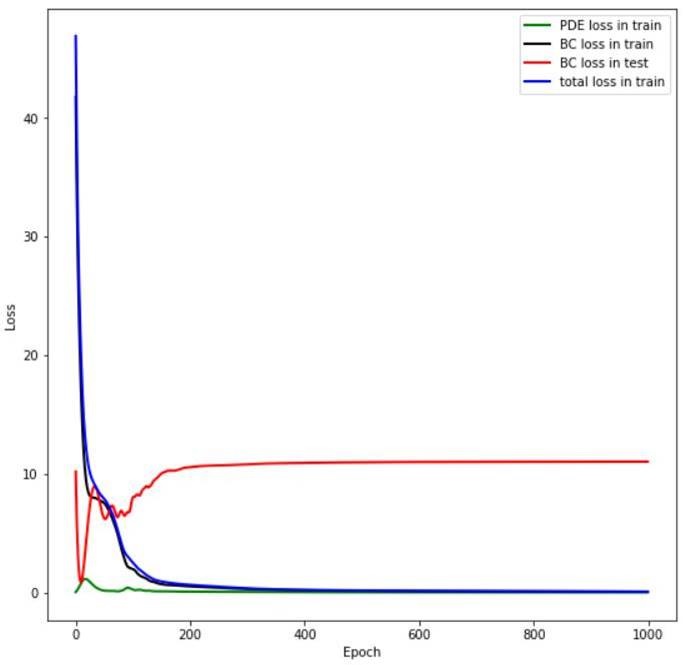
I want to develop a Physics informed neural network model in Pytorch. My network should be trained based on two losses: boundary condition (BC) and partial derivative equation (PDE). I am adding these two losses but the problem is that the BC is controlling the main loss, like the following figure:
It’s hard to say given this alone, but since the high BC loss is the only ‘test’ loss in the plot, is this just a case of poor generalisation?
Based on my own work, I found that when your total loss is a linear combination of different sub-losses, you should try and ensure that the sub-losses are on a similar scale. If an average value for sub-loss 1 is 0.01 but for sub-loss 2 it’s 10, the total loss is dominated by the first term, and then when training, it can be expected that the weights will be tuned in the direction that leads to the biggest reduction in the overall loss, i.e., the weights will be tuned to reduce sub-loss 1, not sub-loss 2, because it dominates the loss.
Thanks for dedicating time to my issue. As you mentioned the relation between two sub-losses is more complicated than a simple plus operation!
I went through the git page you posted but still I did not get how I can manage these two losses. Sorry for my confusion.
And then from there, during the training forward passes, you can print out the values of _loss_BC and _loss_PDE and look at the behaviour. You can see whether the loss values are changing at all, how much they’re changing by, is one clearly being prioritised over the other, etc…
Thanks for writing the code for me.
Should I copy the exact loss from my code into the code you have written? I mean how losses are supposed to be calculated? And at the end both losses are added which was the same as what I had before.
Just create the methods for your sub-losses in an overall class like the template I showed. So your lossBC function becomes a method which can be accessed through Ploss._loss_BC(), and the same for the PDE. Then you can obtain the total loss in one call to criterion(.,.) and access the sub-losses easily.
In your original code, it’s not clear which are your predicted values and which are your targets, and it wouldn’t run as presented, for instance, self.loss_function(f,f_hat) is returned but f_hat is not included anywhere etc…
Thanks for your help. f_hat is a tensor of zeros which is used to minimize the error between collocation points of PINN and the numerically calculated values.
Meanwhile, I am using the self.forward of the class for predicting the values and later returning the loss value and if i separate the losses as another class I do not know how to include the method self.forward in it.
I think much of the confusion comes down to poor code structure. You should define your model and your loss functions separately, e.g,
class FCN(nn.Module):
def __init__(self,layers):
super().__init__() #call __init__ from parent class
self.activation = nn.Tanh()
self.loss_function = nn.MSELoss(reduction ='mean')
'Initialise neural network as a list using nn.Modulelist'
self.linears = nn.ModuleList([nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1)])
self.iter = 0
'Xavier Normal Initialization'
for i in range(len(layers)-1):
nn.init.xavier_normal_(self.linears[i].weight.data, gain=1.0)
nn.init.zeros_(self.linears[i].bias.data)
'foward pass'
def forward(self,x):
if torch.is_tensor(x) != True:
x = torch.from_numpy(x)
a = x.float()
for i in range(len(layers)-2):
z = self.linears[i](a)
a = self.activation(z)
a = self.linears[-1](a)
return a
model = FCN(...)
optim = ...
criterion = Ploss(...)
for epoch in epochs:
for x,y in batch:
# zero out gradients
optim.zero_grad()
# fwd pass to calculate output
output = model(x)
# calculate loss
loss = criterion(output,y) # This can be your total physics loss
loss.backward()
# update parameters are backprop
optim.step()
""" Or by doing each part separately.
bc_loss = criterion._loss_BC(output,y)
pde_loss = criterion._loss_PDE(output) # PDE residual based on pred
loss = bc_loss + pde_loss
loss.backward()
"""
Look at existing PyTorch tutorials for more guidance on how to structure your code, from there you will be able to better determine what’s going wrong with the PINNs loss.