I’ve implemented a basic sequential model with a bilinear upsampling layer for semantic segmentation of the CAMVID dataset.
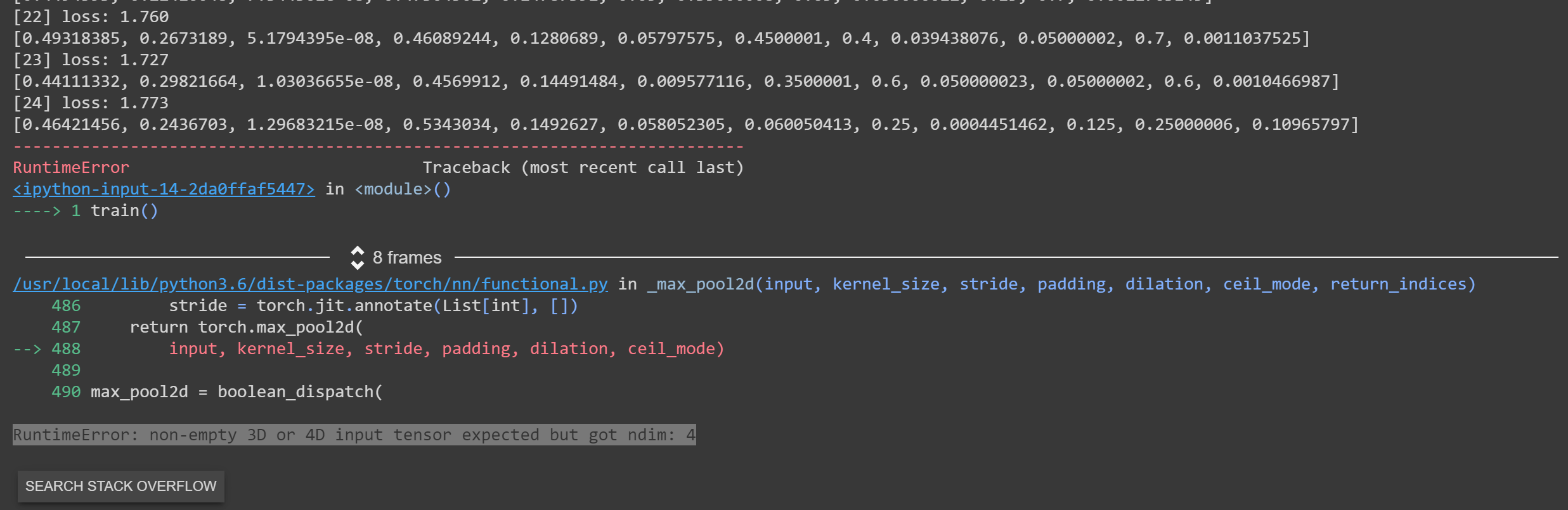
It seems to train fine for about 15-25 epochs before throwing this error:
RuntimeError: non-empty 3D or 4D input tensor expected but got ndim: 4
Why would the tensor shape be wrong after several steps of training as opposed to from step 1?
My code:
#Build model
class VGG16(nn.Module):
def __init__(self,
num_channels = num_channels,
num_classes=num_classes,
init_weights=True,
h=height,
w=width):
super(VGG16, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(512, 4096, 1),
nn.ReLU(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(),
nn.Conv2d(4096, num_classes, 1),
nn.Upsample(scale_factor=30, mode='bilinear'),
)
def forward(self, x):
x = self.encoder(x)
return x
def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m)
m.bias.data.fill_(0.01)
#Prepare Network for Training
network = VGG16()
network.cuda()
network.apply(init_weights)
# Optimizer
optimizer = torch.optim.Adam(network.parameters(), lr=0.005)
# Loss
criterion = nn.NLLLoss()
criterion2 = nn.CrossEntropyLoss(weight=weights(y_train))
#Training Function
def shuffle(x_train, y_train):
perm = torch.randperm(len(x_train))
samples = x_train[perm]
labels = y_train[perm]
return(samples, labels)
#Track Metrics
training_scores = []
validation_scores = []
mean_iou_scores = []
def train(batch_size=20, epochs=100):
n_batches = int(n / batch_size)
for i in range(epochs):
x_shuffled, y_shuffled = shuffle(x_train,y_train)
for j in range(n_batches):
# Local batches and labels
x_batch, y_batch = Tensor(x_shuffled[i*batch_size:(i+1)*batch_size,]), Tensor(y_shuffled[i*batch_size:(i+1)*batch_size,])
optimizer.zero_grad()
y_batch = torch.reshape(y_batch, (-1, height, width))
training_output = network(x_batch.detach().cuda())
loss = criterion2(training_output, y_batch.cuda().long())
loss.backward()
optimizer.step()
# print metrics
prediction = torch.argmax(training_output, dim=1).float()
ious = calc_iou(prediction, y_batch, 12)
mean_iou_scores.append(np.average(ious))
print('[%d] loss: %.3f' %(i + 1, loss))
print(ious)