Hello, I have cuda memory problems while trying to fine tune Siamese BERT on quora question dataset. I am using SentenceTransformers library (https://github.com/UKPLab/sentence-transformers). I launched VM on GCP with 4 GPUS (NVIDIA TESLA P100), and I tried to fine tune it with following code:
train_batch_size = 64
model_name = 'bert-base-nli-mean-tokens'
num_epochs = 4
model_save_path = 'output/training_stsbenchmark_continue_training-'+model_name+'-'+datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
warmup_steps = math.ceil(len(train_data)*num_epochs/train_batch_size*0.1) #10% of train data for warm-up
logging.debug("Warmup-steps: {}".format(warmup_steps))
# Training the model
model.fit(train_objectives=[(train_dataloader, train_loss)],
evaluator=evaluator,
epochs=num_epochs,
evaluation_steps=1000,
warmup_steps=warmup_steps,
output_path=model_save_path)
after 342 iterations I got following error:
/opt/anaconda3/lib/python3.7/site-packages/transformers/modeling_bert.py in forward(self, hidden_states)
326 def forward(self, hidden_states):
327 hidden_states = self.dense(hidden_states)
--> 328 hidden_states = self.intermediate_act_fn(hidden_states)
329 return hidden_states
330
/opt/anaconda3/lib/python3.7/site-packages/transformers/modeling_bert.py in gelu(x)
131 Also see https://arxiv.org/abs/1606.08415
132 """
--> 133 return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
134
135
RuntimeError: CUDA out of memory. Tried to allocate 98.00 MiB (GPU 0; 15.90 GiB total capacity; 13.44 GiB already allocated; 13.88 MiB free; 1.80 GiB cached)
I tried using more GPUs but it always failed, and I started to wonder if maybe there is a problem with not optimal memory allocation in the SentenceTransformers library. On the other hand, BERT model is pretty huge, so considering its siamese model it can be just too big, and I might need to use even more GPUs or distributed training. I’d be really grateful for every suggestion
I’m not familiar with the mentioned repository, but by just skimming through the code it seems multiple GPUs won’t be used?
The fit() function points to this line of code, which will only use the default device.
You could try to lower the batch size and see, if the model still converges as you wish.
Also, you could try to use torch.utils.checkpoint to trade compute for memory, but I’m not sure how easy it would be to implement it in this particular repository, as some higher level abstractions seem to be used.
Thanks, I’m not really familiar with the topic of using multiple GPUs, I thought that this syntax by default splits onto every available GPU. So if I’d like to use all, I should be moving it to every device explicitly, or use model = nn.DataParallel(model)? In case of repository, I think I will have to fork it and change just my nessecary functions/classes, and maybe later on work on it in depth
I tried using nn.DataParallel, but I ran into the same problem. The diagnostics of GPUs looks like this:
Sun Jan 26 12:16:30 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 49C P0 36W / 250W | 16233MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-PCIE... Off | 00000000:00:05.0 Off | 0 |
| N/A 40C P0 28W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P100-PCIE... Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P0 28W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P100-PCIE... Off | 00000000:00:07.0 Off | 0 |
| N/A 42C P0 25W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 7706 C /opt/anaconda3/bin/python 16223MiB |
+-----------------------------------------------------------------------------+
after I used such syntax in fit method of the SentenceTransformer class:
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
logging.info("Use pytorch device: {}".format(device))
self.device = torch.device(device)
self = nn.DataParallel(self)
self.to(device)
It looks like everything is still passed only to first GPU.
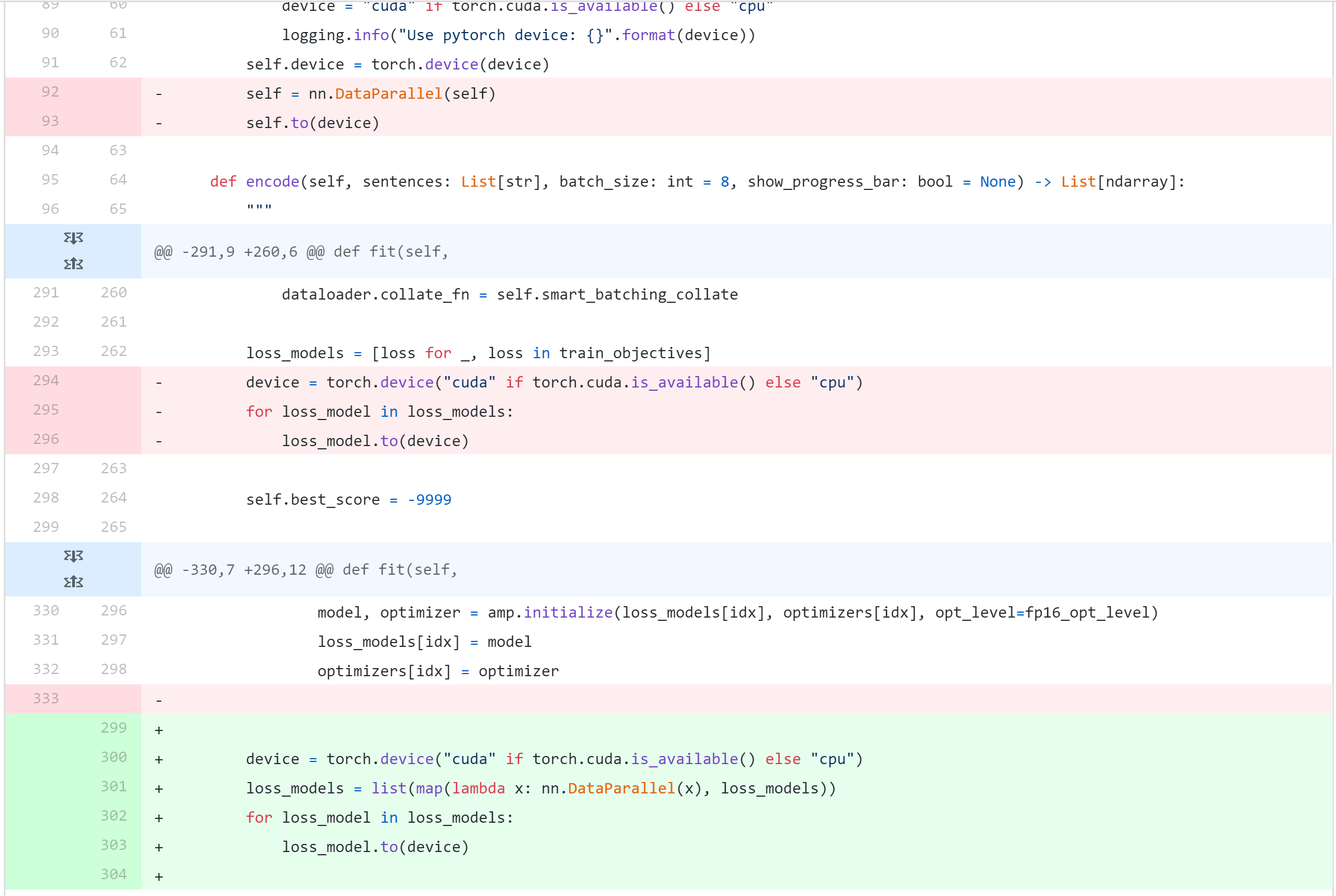
EDIT: I added nn.DataParallel in appropriate block of code (for every loss_model in loss_models, with appropriate changes in them so that they work) and it works, models are being split onto every GPU
Sure, I think everything is in this commit in data_parallel branch of my fork of original repository:
Essentially, I changed these lines of code:
92 self = nn.DataParallel(self)
93 self.to(device)
...
294 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
295 for loss_model in loss_models:
296 loss_model.to(device)
to:
300 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
301 loss_models = list(map(lambda x: nn.DataParallel(x), loss_models))
302 for loss_model in loss_models:
303 loss_model.to(device)
I also changed the CosineSimilarityLoss, but it was mainly because of different training objective I wanted to use, so it’s not nessecary for multiple GPUs. Let me know if you need help, it’s a bit messy but it works
Hello, could you link to/paste whole code with your ‘training_nli_bert.py’ script? There is a problem with shapes of tensors you pass (outputs of your model have different dimensions than your targets)