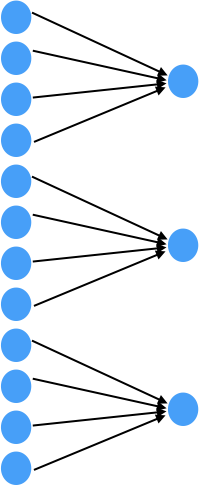
Say I have an input vector with 12 dimensions, I want to output a vector with 3 dimensions. Instead of fully connecting the input and output, I would like to compute the first feature of output based on the first 4 features of the input, and the second dimension of output based on 5th to 8th features in the input vector, and so on.
The output dimension should not be hardcoded, but variable! Therefore I can’t just simply split the input vector to the 3 equal pieces.
Concretely, I want to implement the self multi-head attention pooling in this paper.
I think @benoriol 's method is OK.
Suppose your input shape is (12, ), you can reshape it to (1, 12), then use Conv1D. Conv1D input_channel = 1, out_channel = 1, kernel_size = 4, stride = 4. I just test it by this code:
If I understand the paper correctly, the params of the Heads should not be shared. But if you use Conv1d, you will end up sharing the weights per head.
Yes you are right. As I replied above, I don’t think conv1d is the best solution.
I’m trying the torch.nn.ModuleList instead, but I’m not sure how the computation graph would be built under this manner and how the training and back propagation would be influenced. Do you have any suggestions?
As far as I read the pytorch documentation, the nn.Conv1d should take the 4th argument as stride = head_dim. Do you explicitly left it as here or is it just a typo?
By the way, if I have a audio segment with N frames with 12 dimensions of each, should I modify your code this way:
Well, for the N frames, I think you will have to trick a little bit with reshape:
bs = 1
input_dim = 12
N = 6 # the number of frames
num_heads = 3
head_dim = input_dim // num_heads
input = torch.rand(bs, N, input_dim)
conv = nn.Conv1d(N, N * num_heads, head_dim, head_dim)
h = conv(input)
h = h.reshape(bs, N, num_heads, num_heads)
h = h.diagonal(dim1=2, dim2=3)
Please verify if that is what you want to do.
And keep in mind that there are a lot of extra calculations (it shouldn’t matter that much on the GPU if frame_len and num_heads are small), but there might be a cleaner solution.
conv = nn.Conv1d(N, N * num_heads, head_dim, head_dim)
since the frame lengths in training data are also variable. If you are interested, the following is what I did:
...
def init(...)
...
self._attention = nn.Conv1d(1, self._header_num, self._header_dim,
stride=self._header_dim)
def forward(...)
...
att_list = []
for h in LastHiddenLayerOutput
# h is the hidden layer output with N frames and d dimensions of
# each, i.e. it has the shape [N, d]
# transform it into shape of [N, 1, d] to suit the conv1d input
score = self._attention(h.unsequeen(0).permute(1, 0, 2))
# Thanks for @spanev for your hint about nn.diagonal
score = score.diagonal(dim1=1, dim2=2)
score = nn.Softmax(dim=0)(score)
# Tricky part, split h_a into k(headers) parts and make
# h_a.shape = [d/k, k, N]
# At this step, score.shape = [N, k], capable to matmul with h_a
h_a = h.view(-1, self._head_num, self._head_dim)
h_a = h_a.permute(2, 1, 0)
# matmul of h_a with score has shape of [d/k, k, k],
# only the diagonal of last 2 dim are the sum of attention over all frames
score = torch.matmul(h_a, score).diagonal(dim1=1, dim2=2)
score = torch.flatten(score)
att_list.append(score)
att_h = torch.stack(att_list)
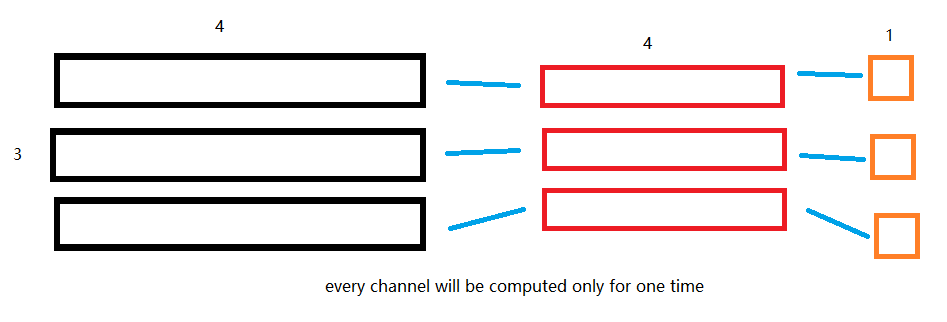
You can set the input in shape like (3,4), and use Conv1D to do the convolution with kernel in shape like (3,4). 1 dimension will be computed for one time to get one output, and you will get three features finally. And it won’t share the weight because of the kernel shape is (3,4) when computing.
You need to set the shape of the kernel as (3,4). For convolution kernel, it will share the weight in the same channel but not between channels, right? Cuz no matter every channel of kernel or input, the size of every channel is 4, and the dimension is 1. So, your input will just compute with the kernel on the same channel for only one time. Finally, we will get three feature maps, cuz the number of channels is three.
And you are right. For one kernel, all results will be added into one. So we can just get one result. So we can just use this kind of way that is one computing with only one in_channel and one out_channel, and input only one vector. To do this operation for three times, we can get three results. But it won’t like what your pic showing, computing all at the same time. But you can set the three in_channels and three out_channels, and use group convolution to make the output of three channels won’t be added into one
Code goes like
import torch
import torch.nn as nn
ind=torch.arange(12,dtype=torch.float32).reshape([1,3,4])
# print(ind)
#
# conv=nn.Conv1d(in_channels=1,out_channels=1,kernel_size=4)
# for data in ind:
# print(conv(data.unsqueeze(0).unsqueeze(0)))
conv=nn.Conv1d(in_channels=3,out_channels=3,kernel_size=4,groups=3)
print(conv(ind))
I don’t think this is how multi head attention pooling works. I suggest you read the paper and pytorch docu carefully.
The conv1d in your first post will result in parameter sharing and the second will cause incorrect output feature computation.
Furthermore, if you are really into this problem, I also strongly recommend you read the code in my previous reply, which I think might be what you actually have in mind.