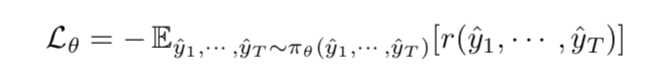Hi, @ptrblck I tried debugging by checking each operation sequentially. Figured out that decoder is essentially the bottleneck because using encoder outputs, I am decoding new predictions at each time-step using previous step prediction and attended inputs (Using LSTM cell). Saving new predictions at each time step in a list is also saving its computation graph which is essentially increasing the memory consumed.
What I want to understand is for the following memory consumption during sequence decoding:
TRAINING ITERATION: 0
Decoding start
allocated: 58M, max allocated: 82M, cached: 102M, max cached: 102M
-- Before Beam Sampling
allocated: 58M, max allocated: 82M, cached: 102M, max cached: 102M
– TimeStep_0 –
-- _prepare_output_projections | Start
allocated: 58M, max allocated: 82M, cached: 102M, max cached: 102M
-- _prepare_output_projections | New Decoder state computed
allocated: 60M, max allocated: 82M, cached: 102M, max cached: 102M
– TimeStep_1 –
-- _prepare_output_projections | Start
allocated: 94M, max allocated: 119M, cached: 156M, max cached: 156M
-- _prepare_output_projections | New Decoder state computed
allocated: 162M, max allocated: 207M, cached: 264M, max cached: 264M
– TimeStep_2 –
-- _prepare_output_projections | Start
allocated: 231M, max allocated: 256M, cached: 266M, max cached: 266M
-- _prepare_output_projections | New Decoder state computed
allocated: 299M, max allocated: 344M, cached: 374M, max cached: 374M
…
…
– TimeStep_19 –
-- 1) _prepare_output_projections | Start
allocated: 2395M, max allocated: 2420M, cached: 2442M, max cached: 2442M
-- 4) _prepare_output_projections | New Decoder state computed
allocated: 2464M, max allocated: 2508M, cached: 2548M, max cached: 2548M
-- After Beam Sampling
allocated: 2529M, max allocated: 2530M, cached: 2550M, max cached: 2550M
TRAINING ITERATION: 1
Decoding start
allocated: 214M, max allocated: 2600M, cached: 2664M, max cached: 2664M
-- Before Beam Sampling
allocated: 214M, max allocated: 2600M, cached: 2664M, max cached: 2664M
– TimeStep_0 –
-- _prepare_output_projections | Start
allocated: 214M, max allocated: 2600M, cached: 2664M, max cached: 2664M
-- _prepare_output_projections | New Decoder state computed
allocated: 218M, max allocated: 2600M, cached: 2664M, max cached: 2664M
– TimeStep_1 –
-- _prepare_output_projections | Start
allocated: 307M, max allocated: 2600M, cached: 2786M, max cached: 2786M
-- _prepare_output_projections | New Decoder state computed
allocated: 429M, max allocated: 2600M, cached: 2850M, max cached: 2850M
– TimeStep_2 –
-- _prepare_output_projections | Start
allocated: 605M, max allocated: 2600M, cached: 2974M, max cached: 2974M
-- _prepare_output_projections | New Decoder state computed
allocated: 727M, max allocated: 2600M, cached: 3036M, max cached: 3036M
…
…
– TimeStep_33 –
-- 1) _prepare_output_projections | Start
allocated: 9839M, max allocated: 9899M, cached: 9958M, max cached: 9958M
-- 4) _prepare_output_projections | New Decoder state computed
allocated: 9962M, max allocated: 10006M, cached: 10074M, max cached: 10074M
-- After Beam Sampling
allocated: 10136M, max allocated: 10137M, cached: 10196M, max cached: 10196M
_prepare_output_projections is the function that computes new decoder state (h_t, c_t) using previous step prediction and attended input. The function also returns new predictions by projecting h_t, output of LSTM cell into the vocabulary space.
At each time-step, I am predicting for batch_size x beam_size sequences. That is, if batch_size = 8 and beam_size = 100, I am making 8x100 = 800 predictions at each time step. Above stats are shown for batch_size = 2 and beam_size = 32. Max_time_steps_allowed = 50
I can see that with increase in number of predictions, allocated memory increases. Is there something wrong, or is this is the expected behaviour? I want to experiment with batch_size =16 for stable training. Should I go with gradient accumulation? Please, advise.