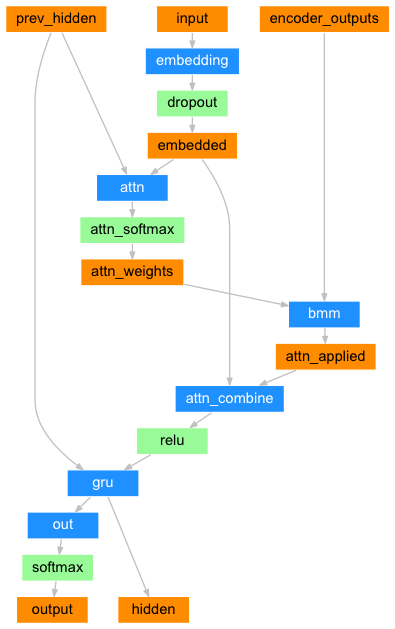
Hello, I’m studying attention mechanism via “TRANSLATION WITH A SEQUENCE TO SEQUENCE NETWORK AND ATTENTION”.
But I have a problem to understand the below image. [prev_hidden] indicates decoder hidden state and [input] indicates decoder input, how these two tensors make attention weight?
I thought decoder hidden state and all hidden states of encoder make attention weight in Attention mechanism. So how decoder hidden state and decoder input?
There are different approaches towards attention. If I remember correctly, this tutorial implements the Bahdanau Attention. Very popular is also Luong Attention, which is arguably simply, at least with respect to coding – I don’t make any claims about effectiveness.
This Stackoverflow post discusses both approaches and contains good illustrations and additional links to other good sources.
No, that is not true. The main difference between Bahdanau Attention and Luong Attention is that Bahdanau attention is additive attention and Luong Attention is dot-product attention. But their inputs are the same: the encoder output and the decoder hidden state.
so the question still remains, why in this tutorial the author use decoder hidden state and decoder input as the inputs to compute attention weights?
So let the decoder’s hidden state be kt and the encoder’s be ht and let T be the length of the encoder input. Let yt be the decoder’s input and xt be the encoder’s inputs and zt be the decoder’s targets.
Loung Attention computes attention between k_t and h_1, h_2, …, h_{T} and gives various formulas.
Bahdanau gets the attention between k_{t-1} and h_1, …, h_{T} and uses some tanh.
The point is you are time step t and want to predict zt. What do you have access to? You have k_{t-1}, y_{t} and h_1, …, h_{T} and all of the encoder’s inputs (x_1, …, x_T) and you’d like to predict z_{t}.
To do this, you form some vector c_{t} via some sort of weighted average of the vectors h_{s}, the encoder hidden states. For example,
Or, k_t = G(k_{t-1}, y_t) and then c_t = sum_{s=1}^{T}{h_s * F(k_t, h_s)}
G can be a GRU cell above and F is some sort of normalized scoring metric. If you consider F(k_t, h_s) you can compute an inner product dot(k_t, h_s) for each s in {1,…, T} and then normalize by softmax to get probabilities, for example.
The format of F can be anything you like. Also, the ARGUMENTS to F can be anything you like so long as you don’t look ahead: the part associated with the decoder in computing F can be (k_t), or (k_{t-1}, y_t), or (k_{t-1}, k_{t-2}, y_{t-2}), whatever, you know all these at time step t and you are not using forward information. This tutorial uses (k_t, y_t), and that’s fine. I guess you want to keep all the information when you cross h_s with (k_t, y_t). You could have also crossed h_s with k_t since k_t has y_t’s information since k_t = GRUCell(k_{t-1}, y_t), it is a function of k_{t-1} and y_t, but this is up to you. You have options to do as you like but you have the above restriction with not looking ahead …