Hi,
I have a time series dataset consisting 72 input values and 72 output values for each entry and I’m trying to train a seq2seq Encoder Decoder network that forecasts the output using the input. Here’s what I have so far.
model;
import torch
import torch.nn as nn
import torch.nn.functional as F
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, n_layers, dropout=0.1):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = n_layers
self.gru = nn.GRU(input_size=input_size, hidden_size=hidden_size,
num_layers=n_layers, dropout=dropout)
def forward(self, input):
self.gru.flatten_parameters()
hidden = torch.zeros(self.num_layers, 1, self.hidden_size).cuda()
_, hidden = self.gru(input.unsqueeze(1), hidden)
return hidden
class DecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size, n_layers, dropout=0.1):
super(DecoderRNN, self).__init__()
self.gru = nn.GRU(input_size=output_size, hidden_size=hidden_size,
num_layers=n_layers, dropout=dropout)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
self.gru.flatten_parameters()
output = input.unsqueeze(1).unsqueeze(1)
output, hidden = self.gru(output, hidden)
output = self.out(output)
output = output.squeeze()
return output, hidden
class Seq2Seq(nn.Module):
def __init__(self, hidden=256, n_layers=2, dropout=0.1):
super().__init__()
self.encoder = EncoderRNN(72, hidden, n_layers, dropout)
self.decoder = DecoderRNN(1, hidden, n_layers, dropout)
def forward(self, src):
outputs = torch.zeros(src.shape[0], src.shape[1]).cuda()
hidden = self.encoder(src)
input = src[:,-1]
output, hidden = self.decoder(input, hidden)
outputs[:,0] = output
for t in range(1,src.shape[1]):
input = src[:,t]
output, hidden = self.decoder(input, hidden)
outputs[:,t] = output
return outputs
simplified training code;
import torch.optim as optim
import torch.utils.data as loader
import data as datapy
trainloader = ...
testloader = ...
model = Seq2Seq(hidden=144, n_layers=2, dropout=0.1)
model.cuda()
mse = torch.nn.MSELoss(reduction='mean').cuda()
optimizer = optim.SGD(model.parameters(), lr=0.001)
num_epochs = 5
for epoch in range(1,num_epochs+1):
model.train()
for i, data in enumerate(trainloader, 1):
input = data[:,:72].cuda()
target = data[:,72:].cuda()
model.zero_grad()
outputs = model(input, target)
loss = mse(outputs, target.float())
loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 0.03)
optimizer.step()
model.eval()
with torch.no_grad():
for i, data in enumerate(testloader, 1):
input = data[:,:72].cuda()
target = data[:,72:].cuda()
outputs = model(input, target)
loss = mse(outputs, target)
Starting from first epoch the network gets stucked at some point and changing lr doesn’t seem to be solving the issue. My dataset consists of only a sensor’s measurements which are always non-zero. My data loader basically normalizes it by dividing each measurement by the maximum_value/2. Any data tensor dataloader gives has the shape of [batch_size, 144], 144 meaning 144 hours of data, I split them by 72 and 72 on train and test runs.
Here’re some plots showing two separate single forward passes for entries from both training and test sets.
Train; blue: actual data, green: forecasts
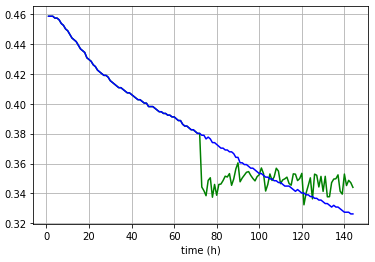
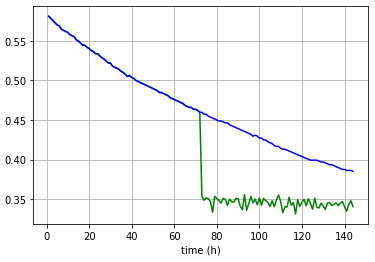
Test;
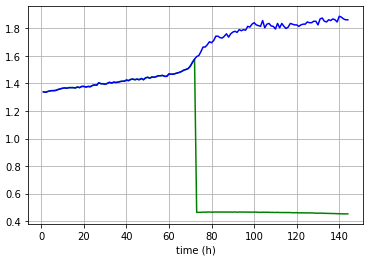
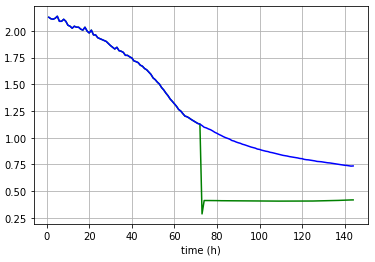
Outputs are not exactly same but they are a straight line all the time.
I’m open to any suggestions regarding the network and/or the training process.