Hello dear community,
I’d like to ask for your advise/expertise on an issue that I am currently facing.
Summary:
I am training a Seq2Seq model that generates a natural language question based on a graph. Train and validation loss are decreasing throughout training but predicting questions outputs nonsense.
Context:
My goal is to create a model that is capable of generating a question given a small ‘question graph’, that represents some semantic context. For example, a question graph such as (Person) - [acts in] - (Movie) - [directed by] - (Director) (think of paths that can be matched using Cypher in Neo4j), could result in a question like Who acts in the movie that is directed by the director? Considering node attributes and copying them into the generated question can be ignored for now.
My Approach:
Using a question dataset (currently all questions from HotpotQA), i generate a question graph for each question using algorithmic approaches (NER & Entity Tagging for nodes and Dependency Parsing for edges). This works fine. Combined with the original questions, which the question graphs originate from, I now have a set of training pairs (question graph - question), that I am using to train a Seq2Seq model as such:
- Encoder: GNN, that outputs a single graph embedding for each question graph. Each node and edge is initialized using pre-trained word embeddings (Conceptnet Numberbatch). It has a single GNN layer (NNConv from Pytorch Geometric) to prevent over-smoothing of node embeddings, since question graphs consist of about 3-4 nodes. This layer makes use of edge embeddings that encode the edge labels (e.g
acts inanddireced by). - Decoder: RNN, with the initial hidden state being the graph embedding of the Encoder. I use a GRU layer with a learnable embedding layer. Vocabulary is processed by keeping only words with a minimum word frequency (say 8 occurences).
Problem:
The underlying issue is that I can optimize the loss, but when examining the generated questions, they neither make sense grammatically nor do generated words seem to be related to the question graph (only very vaguely). Even predicting on the trainset does not improve that quality. Also, in terms of generating nice questions, I am not able to overfit the model (by disabeling dropout, using complex model and many many epochs).
What I have tried/observed:
- I trained using various number of training pairs (1k - 60k). All show similar behaviour.
- I tested various parameters: vocab size, batch size (16-128), teacher forcing (0.1 to 0.5) and especially learning rates (including scheduling) ranging from 0.1 to 0.001.
- Various model complexities (dropout from 0.2 to 0.5), stacking 1 2 or 3 GRU layers
- I typically notice high oscillations of validation loss in early training. Interestingly, these oscillations persist when I use the train data for evaluation (Hints given here regarding this couldn’t help me: machine learning - Why is the validation accuracy fluctuating? - Cross Validated)
- I noticed that predictions are generally much shorter than the actual question and often contain very repetitive patterns.
- While loss curves behave differently, the generated questions are of similar (low) quality.
Example Outputs:
(For context: The “MASK_” tokens are predictions of nodes. During preprocessing, I replace all Named Entities with their corresponding label (e.g. Who visited Michael last weekend? would result in MASK_Person visited MASK_Person last MASK_DATE?) Since I do not adopt a classical Copy Mechanism to copy attribute names from the question graph, I instead predict their node labels (which are part of the vocabulary) which i replace with node attributes later in my architecture)
Actual: What type of series was the 2010 series which starred a Hong Kong actress born in 1970?
Predicted: ['which', 'was', 'a', 'of', 'a', 'the', 'in']
Actual: Which film was made first Portrait of Gina or Crazy Love?
Predicted: ['the', 'MASK_Movie', 'a', '?', 'a']
Actual: DJ Fisher was an agent for which basketball player whose name means “special blessing”?
Predicted: ['which', 'was', 'a', 'UNK', '?']
Actual: What year did the group who sung “Another Rainy Day in New York City” form?
Predicted: ['what', 'MASK_MusicGroup', 'a', 'the', 'that']
Actual: The song Lifted by Love was included in the soundtrack of a film directed by who ?
Predicted: ['which', 'was', 'a', 'the', 'a', 'of', 'a']
Actual: Huh Jung directed a South Korean horror film that was released on what day in 2017?
Predicted: ['what', 'directed', 'did', 'the', 'MASK_Nationality', 'in', '?', 'in']
Actual: What Indian Constitution established authority estimated the money scandal around the 2G Spectrum scam?
Predicted: ['when', 'did', 'was', 'has', 'that']
Actual: Dolomedes briangreenei has been named after which American theoretical physicist and mathematician?
Predicted: ['the', 'of', 'MASK_Ordinal', '?']
Actual: Who released the album on which Outro is the final track?
Predicted: ['the', 'what', 'is', 'the', 'the', 'the', 'that']
Here are two representative training curves, that I obtained and lead to equally quality output like above:
A: Loss curves. Using 10K samples, inital lr=0.065, low complexy Decoder (single GRU, single dropout of 0.25, batch_size=128)
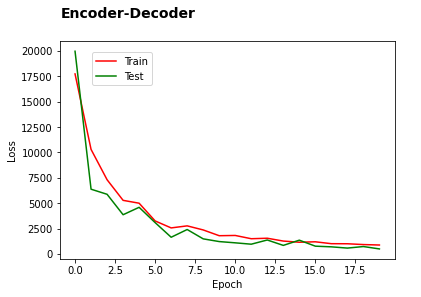
B: Loss curves. Using 20K samples, initial lr=0.065, higher complexity Decoder (3 GRU, two dropout of 0.4, batch_size=128) [As a new user, I can not post two images. But the curves are very similar, except validation starts of at around 8x higher than train loss, and oscillates much more than in A)
Encoder & Decoder:
Encoder GNN:
class QuestionGraphGNN(torch.nn.Module):
def __init__(self, in_channels=301, hidden_channels=256, out_channels=(vocab size), dropout=0.4, aggr='mean'):
super(QuestionGraphGNN, self).__init__()
nn1 = torch.nn.Sequential(
torch.nn.Linear(in_channels, hidden_channels),
torch.nn.ReLU(),
torch.nn.Linear(hidden_channels, in_channels * hidden_channels))
self.conv = NNConv(in_channels, hidden_channels, nn1, aggr=aggr)
self.lin = nn.Linear(hidden_channels, out_channels)
self.dropout = dropout
def forward(self, x, edge_index, edge_attr):
x = self.conv(x, edge_index, edge_attr)
x = F.leaky_relu(x)
x = F.dropout(x, p=self.dropout)
x = self.lin(x)
return x
Decoder RNN:
class DecoderRNN(nn.Module):
def __init__(self, embedding_size, output_size, dropout=0.4):
super(DecoderRNN, self).__init__()
self.output_size = output_size
self.dropout = dropout
self.embedding = nn.Embedding(output_size, embedding_size)
self.gru1 = nn.GRU(embedding_size, embedding_size)
self.gru2 = nn.GRU(embedding_size, embedding_size)
self.gru3 = nn.GRU(embedding_size, embedding_size)
self.out = nn.Linear(embedding_size, output_size)
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, inp, hidden):
output = self.embedding(inp).view(1, 1, -1)
output = F.leaky_relu(output)
output = F.dropout(output, p=self.dropout)
output, hidden = self.gru1(output, hidden)
output = F.dropout(output, p=self.dropout)
output, hidden = self.gru2(output, hidden)
output, hidden = self.gru3(output, hidden)
out = self.out(output[0])
output = self.logsoftmax(out)
return output, hidden
The training loop follows the implementation of this tutorial: NLP From Scratch: Translation with a Sequence to Sequence Network and Attention — PyTorch Tutorials 2.2.0+cu121 documentation
The Loss is torch.nn.NLLLoss.
Thank you for taking time to read this post. I have already learned a lot throughout this roject but at this point, I feel like I reached a point at which I am out of ideas to improve. Any advice into which road to take is appreciated.