Hi there!
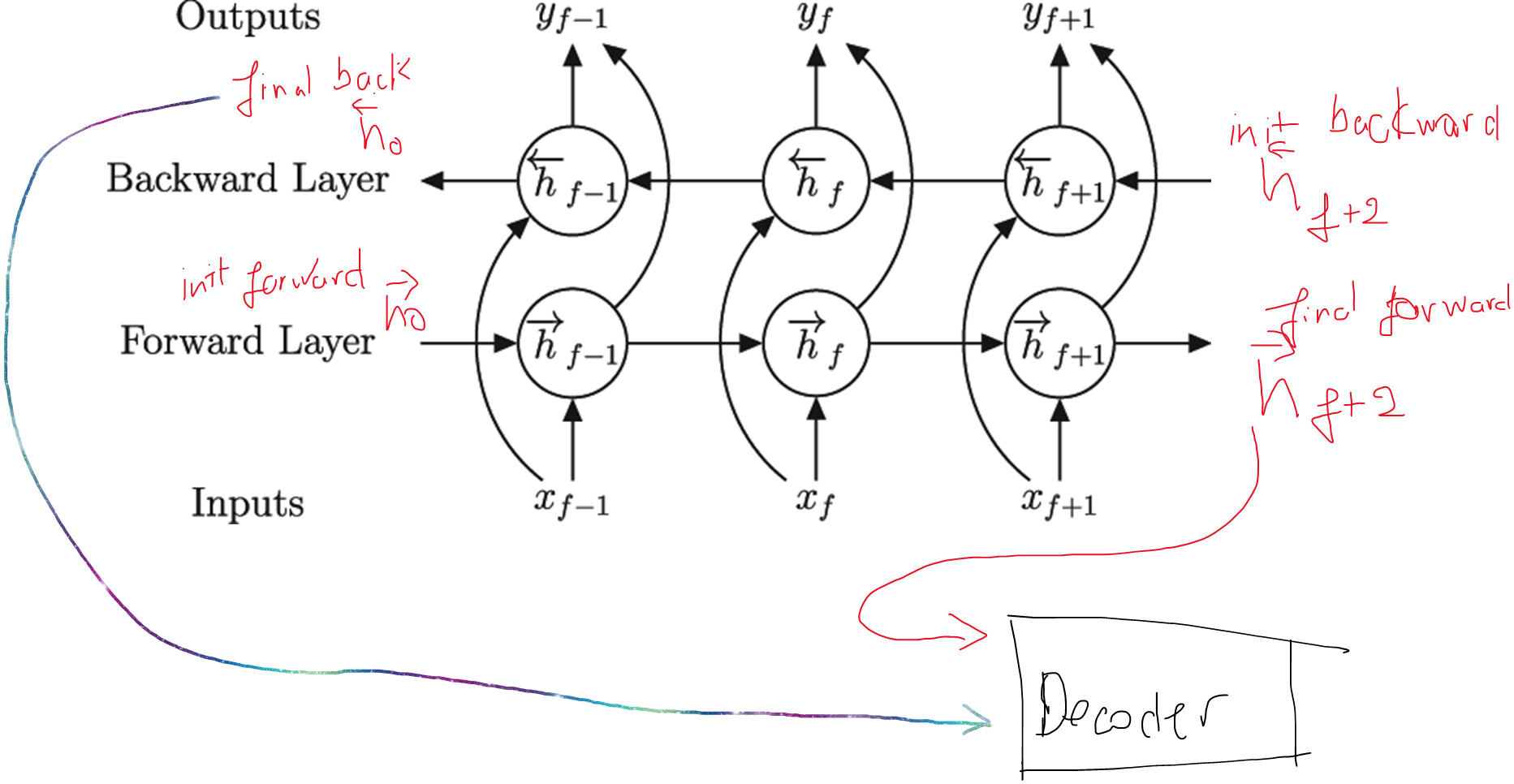
I’m reading the Chatbot Tutorial, and encounter this line of code in the training function that confuses me: # Set initial decoder hidden state to the encoder's final hidden state decoder_hidden = encoder_hidden[:decoder.n_layers]
As far as I know (and tested), the hidden states of Pytorch Bidirectional RNNs (vanilla RNN, GRU, LSTM) contains forward and backward directions alternatively (e.g. we have [4 layers*2 directions, N,h], then the hidden states of forward directions are stored in [0],[2],[4].[6] and backward directions are [1],[3],[5],[7]). AND the backward hidden states are stored only the first sequence (initial timestep)
However, the line of code above passes [0:3] (if n_layers of decoder = 4), meaning that it passes the backward hidden states of the initial timestep (of the 1st and 2nd layer) into the decoder, along with the forward hidden states of the 1st and 2nd layer
QUESTION:
Shoundn’t only the forward hidden states (at timestep Tx) be passed into the decoder, or be the mean or sum between the forward and backward directions rather than passing like the line of code?
Hm, I can see why the code would run, but I don’t like it.
For one, shouldn’t it be encoder_hidden[:-decoder.n_layers] (i.e., with the minus sign)? For example, if the encoder has 5 layers and the decoder just one, encoder_hidden[:1] would be referring to the first layer of the decoder.
Also the encoder can be bidirectional (default), but the decoder must be unidirectional. Do for example, if the encoder is bidirectional but with only 1 layer, and the decoder has 2 layers, the 1st encoder layer will be initialized with the last hidden state of the forward pass, and the 2nd decoder layer will be initialized with the last hidden state of the backward pass. I’m mean, sure, it works, it just doesn’t seem intuitive to me.
So either I’m missing something – more than likely – or I just don’t like that snippet of the implementation :).
I agree with passing hidden states of last layers, but I still am with my idea
Shoundn’t only the forward hidden states (at timestep Tx) be passed into the decoder, or be the mean or sum between the forward and backward directions rather than passing like the line of code encoder_hidden[:decoder.n_layers]?
The main purpose of the decoder to generate/encoder the input sentence into a latent representation, which is often the just the last hidden state of the RNN/LSTM/GRU layer.
How this latent representation is generated, is actually not that important – meaning, you could even use only the backward pass of the input sentence. As such, there’s no principle reason to use only the last hidden state of the backward pass as the initial state of the decoder.
Yes, personally I would go with the mean or some of the last hidden states of the forward and backward pass.
As soon as the decoder has multiple layers, there additional approaches. For example, you could take only the last hidden state of the forward/backward/both pass of the final layer, and the repeat it decoder.n_layers time to serve as initial hidden state of the decoder.
These are good and important questions that I feel get often a bit neglected, at least when I sometimes look into some Github repositories. It’s too convenient to be happy with solution that doesn’t throw an error and kind of works (i.e., it’s training seemingly well).
I’m pretty sure that many adopt the Chatbot tutorial “as is” without trying to dig deep another to understand each step. Again, there’s the chance I’m missing something, but I think to current code – i.e., the line you’ve pointed out – is suboptimal or even wrong.
Well, yes, I would argue that it is wrong, as it does not matter how many layers the encoder have since encoder_hidden[:decoder.n_layers] will always take the “lowest” layers.