I am trying to implement models from the paper Unsupervised Learning of Video Representations using LSTMs.
In particular, the authors describe a encoder-predictor LSTM model (see image below) where the sequence is first encoded and the next steps of the sequence are then predicted. When doing the predictions, at each time step they feed the input either the ground truth of the last step (training time) or the predicted output of the last step (testing time).
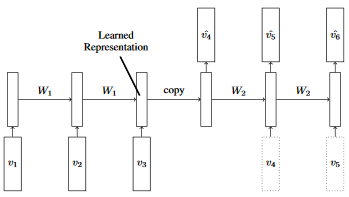
While it seems straightforward to implement the training stage, I am stuck with the testing stage. How to dynamicaly feed the output of a step to the input of the next step? I could do a for loop and computing the steps by hand one after the other, but it does not seem very sweet.
What do you think?