The MPS backend has been in practice for a while now, and has been used for many different things. People discovered where it best performs, and places where the CPU is still faster. In machine learning, certain recurrent neural networks and tiny RL models are run on the CPU, even when someone has a (implicitly assumed Nvidia) GPU. I’m interested in whether that’s because they have matrix multiplications with shapes that mess with GPU caches, or because the overhead of exclusively CUDA CUDA, OpenCL, or Metal driver calls dwarfs the gains of supermassive processing power.
To best explain, I will provide an example. This may not reflect an actual workflow, but it’s a mathematical demonstration. Say that while training a medium-sized RNN, you’re using time series data. You have to run 10,000 loops of a small section of code before the model is fully trained. In each loop, you have one matrix multiplication and five pointwise operations (adds, negates, sigmoids, etc). Based only on a CPU’s FLOPS and bandwidth, the MMX would take 100 μs (microseconds) to complete and the pointwise ops would each take 1 μs. With your GPU that has 100x the FLOPS and 10x the bandwidth, they would take 1 μs and 0.1 μs respectively. But the overhead of dispatching each operator eagerly on the GPU is 50 μs.
Doing the math, one loop takes the following amount of time on each processor. Although we’re working with sub-millisecond units of time, they compound when a loop repeats 10,000 times.
CPU: 1 x 100 μs (MMX) + 5 x 1 μs (pointwise) = 105 μs
GPU: 1 x (50 + 1) μs (MMX) + 5 x (50 + 0.1 μs) (pointwise) = 301.5 μs
Thus, the GPU runs ~3 times slower than the CPU. This overhead could be alleviated if you instead compiled the model into a graph like TensorFlow v1. PyTorch has some lazy tensor functionality, but it seems LazyTensor hasn’t been brought to Metal yet. I see no evidence that the Metal backend is constructing supermassive MPSGraph’s and JIT compiling them. Regardless, not every bottleneck caused by GPU driver overhead can be fixed by calling mark.step(). For example, if you just want to iterate through the loop 5 times. The time spent compiling your MPSGraph (several milliseconds) would vastly exceed 5 x 115 μs.
I’ve been working on a proof-of-concept Metal GPGPU backend. Examining PyTorch’s backend, it is missing some of the optimizations I either already implemented or definitively proved were possible. One was where I reduced amortized driver overhead from 80 μs per operation to 2 μs per operation (two orders of magnitude faster). That’s a theoretical minimum, likely slower in practice because of memory allocations, shader objects not being pre-warmed, etc. Another optimization (not yet POC’ed) automatically fuses unary operations, without requiring LazyTensor or graph mode, because Swift’s automatic memory deallocation lets me turn unused tensors into graph placeholders. Python could benefit from this optimization because it’s partially ARC; only GC for reference cycles. This will cut down on pointless memory allocations for intermediate tensors in complex activation functions, and reduce use of main memory bandwidth. A lot of different optimizations to cover, but the point is: it should measurably reduce the number of scenarios where the GPU runs slower than the CPU.
This isn’t part of PyTorch, but I’m wondering if optimizations I explore could one day be integrated into PyTorch. I won’t invest significant time into the integration myself, but perhaps another contributor will. This could greatly speed up certain workflows, possibly to the point where you don’t have to worry about which ops run faster on the CPU, and which run faster on the GPU. Perhaps Intel GPUs will become measurably faster than (presumably multi-threaded?) CPU, and PyTorch will finally let Intel Mac users use their Intel GPU for machine learning. Conversely, I have used an idea from PyTorch - their highly optimized zero-cost Metal memory allocator, sourced from their experience with CUDA. This magnitude of cross-project collaboration happened before, when Swift for TensorFlow contributed to the inception of torch_xla/LazyTensor. It seems reasonable that it can happen again.
But before that is even considered, is there proof PyTorch’s MPS backend has opportunity for improvement? Do people have models that they tried to run on MPS, but found they were slower on the CPU? If you can figure out what low-level MPSGraph ops a Python program translates to, then divide the total execution time by that number, then you have the sequential throughput. I hypothesize that the minimum throughput is over 25 μs because that’s how long it takes to dispatch one MTLCommandBuffer and with a one-operation MPSGraph. If this hypothesis is correct, there’s room for it to become 10x faster in certain scenarios.
One more thing: OpenCL
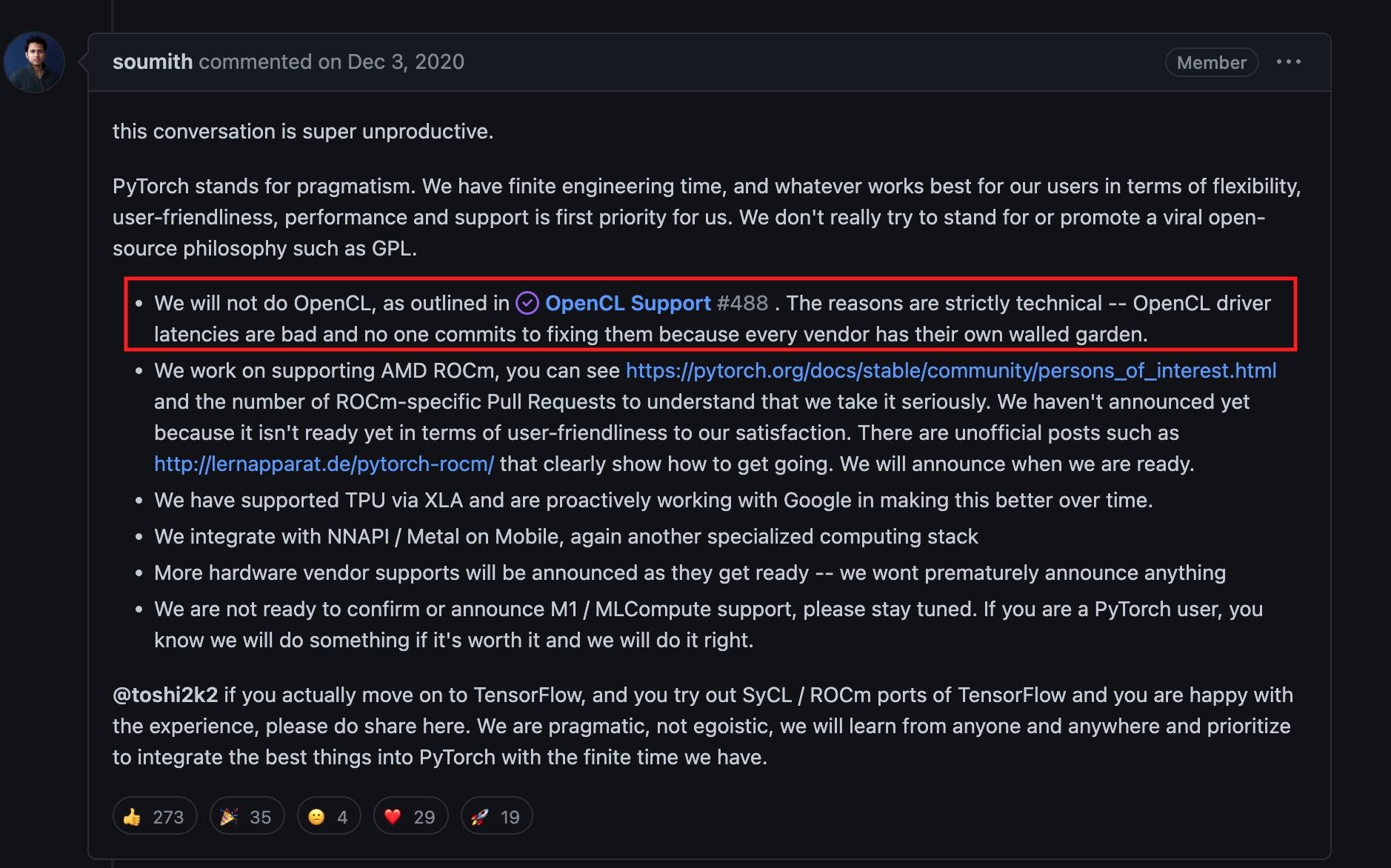
Many of the Metal optimizations I’m researching are applicable to OpenCL, in fact I will apply them to OpenCL. If this reduces amortized driver latencies from “bad” to virtually nothing, PyTorch now has motive to create an in-tree OpenCL backend, utilizing AMD and (please also Intel) GPUs on Windows on Linux. There’s also a high-performance OpenCL matrix multiplication kernel library, rivaling MPS in scope. With both of these puzzle pieces in place, it should take a lot less time and money to support an OpenCL backend for PyTorch users who are very “vocal” about wanting it. Python TensorFlow can already run on these platforms with DirectML, so PyTorch is falling behind its competitor.