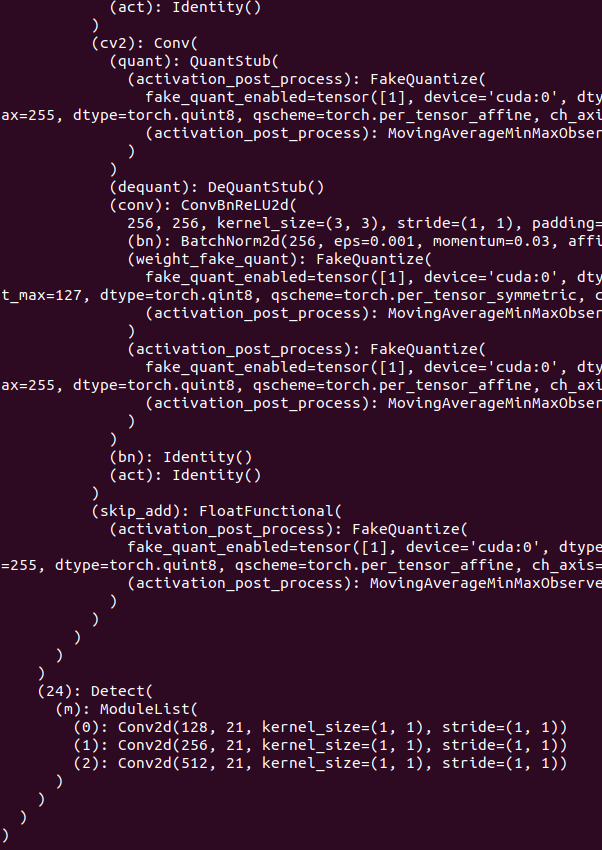
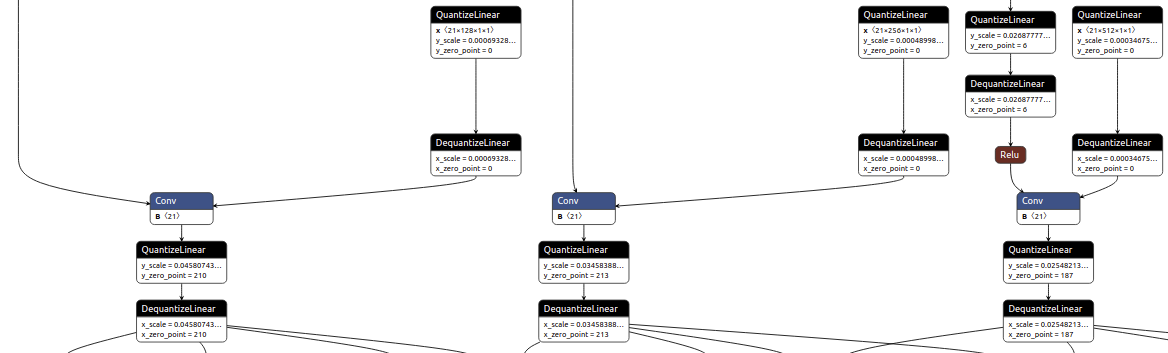
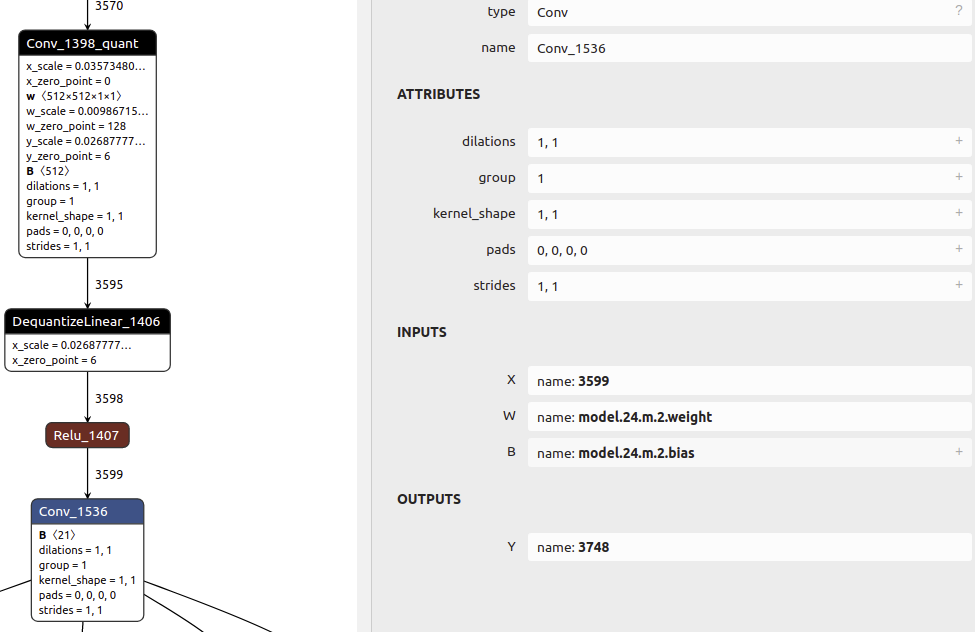
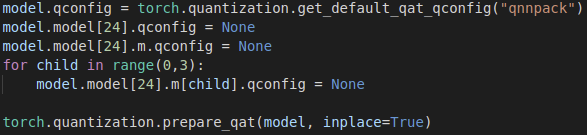
How do i have the Detect layer be fully non-quantized?
I am doing this as the post processed QAT model does not have weights attached to the Conv2Ds of the Detect layer, which I am guessing is causing further exporting issues? The ‘+’ sign is missing form the weights
can you provide more context? how are you quantizing the model exactly, its hard to answer about what’s going wrong without understanding what you are specifically doing.