Hi,
I have a very basic code to train a linear regression model. The code seems to work and it reacts as expected to the modifications of the learning rate. However I have noticed that I do not understand the evolution of the model’s parameters during the training.
Here is the code I use:
import pandas as pd
import torch
torch.manual_seed(42)
# generate some sample data
X = torch.rand(100, 1)
y = 2 * X + 1
# initialize model, loss and optimizer
model = torch.nn.Linear(1, 1)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# train the model
num_epochs = 100
stats_params = {"weight": [model.weight.item()], "bias": [model.bias.item()]}
for epoch in range(num_epochs):
# Forward pass
outputs = model(X)
loss = criterion(outputs, y)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# store model's parameters
stats_params["weight"].append(model.weight.item())
stats_params["bias"].append(model.bias.item())
pd.DataFrame(stats_params).plot()
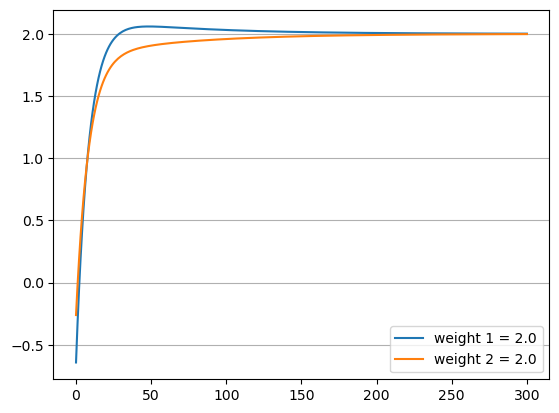
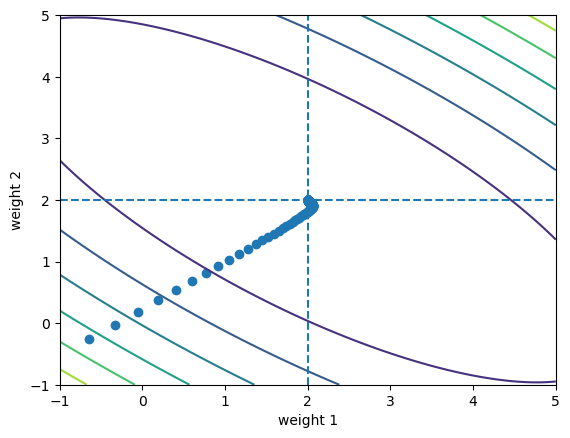
And here is the plot of the model’s parametrs evolution during the training:
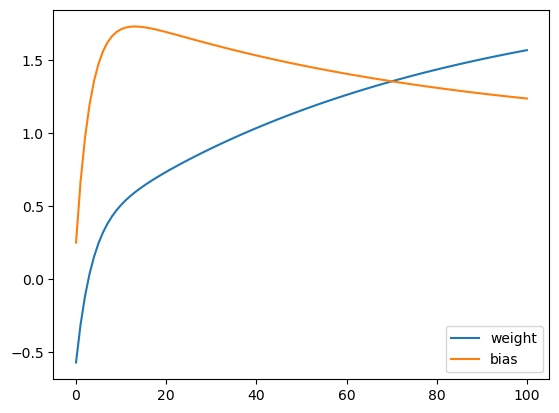
Given that the initial value of bias is below its true value 1, I would expect that in the process of model training it should monotonically increase and asymptotically tend towards the true value. As you can see, this is not what happens.
So is there an error in my code or is this evolution of the model’s parameters expected?