Dear community,
I’ve been playing with VAE for a while and noticed that a shallow 4-layer MLP network performs better than a 6-layer MLP network, and much better than a 18-layer ResNet style VAE with conv and deconv layers.
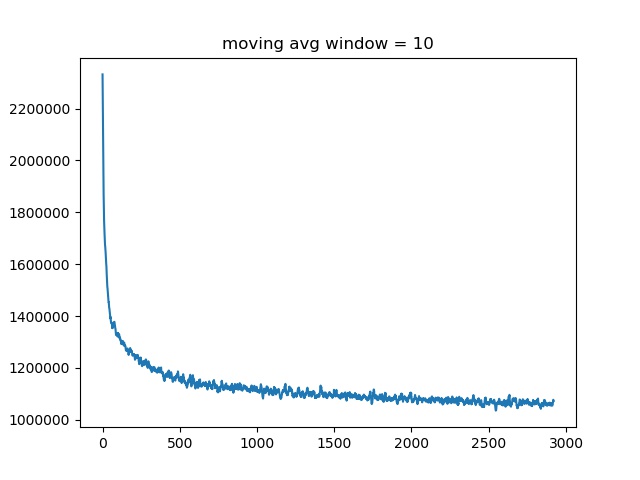
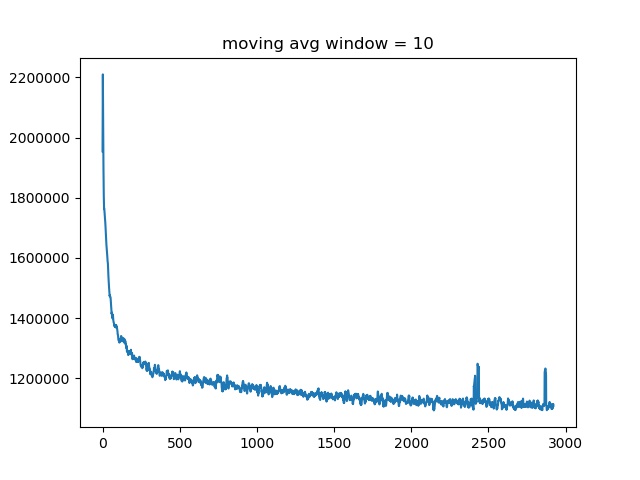
Attaching two loss curves for training a VAE with 4 layer MLP (upper) and 6 layer MLP (lower). The one with more layers have a higher loss as well as bumpy losses towards the end of training.
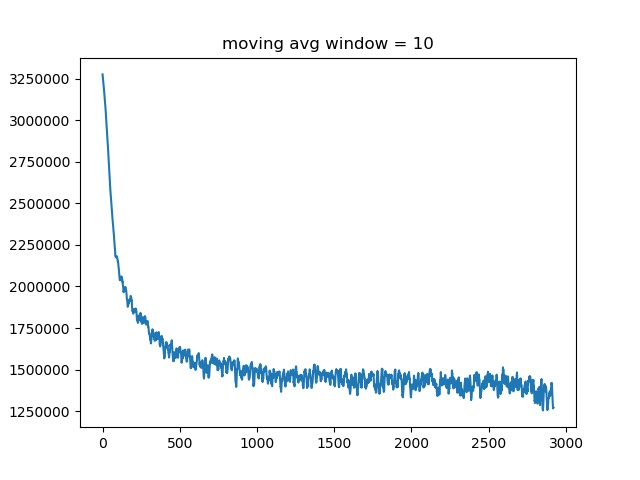
While for the 18-layer ResNet VAE, the loss goes like this and the model only outputs means.

Original picture…
