Hey guys,
The documentation for the Conv3d module states that inputs and output can be grouped together, each group with its own set of weights:
groups - controls the connections between inputs and outputs. in_channels and out_channels must both be divisible by groups.
At groups=1, all inputs are convolved to all outputs.
At groups=2, the operation becomes equivalent to having two conv layers side by side, each seeing half the input channels, and producing half the output channels, and both subsequently concatenated. At groups=in_channels, each input channel is convolved with its own set of filters (of size out_channels // in_channels).
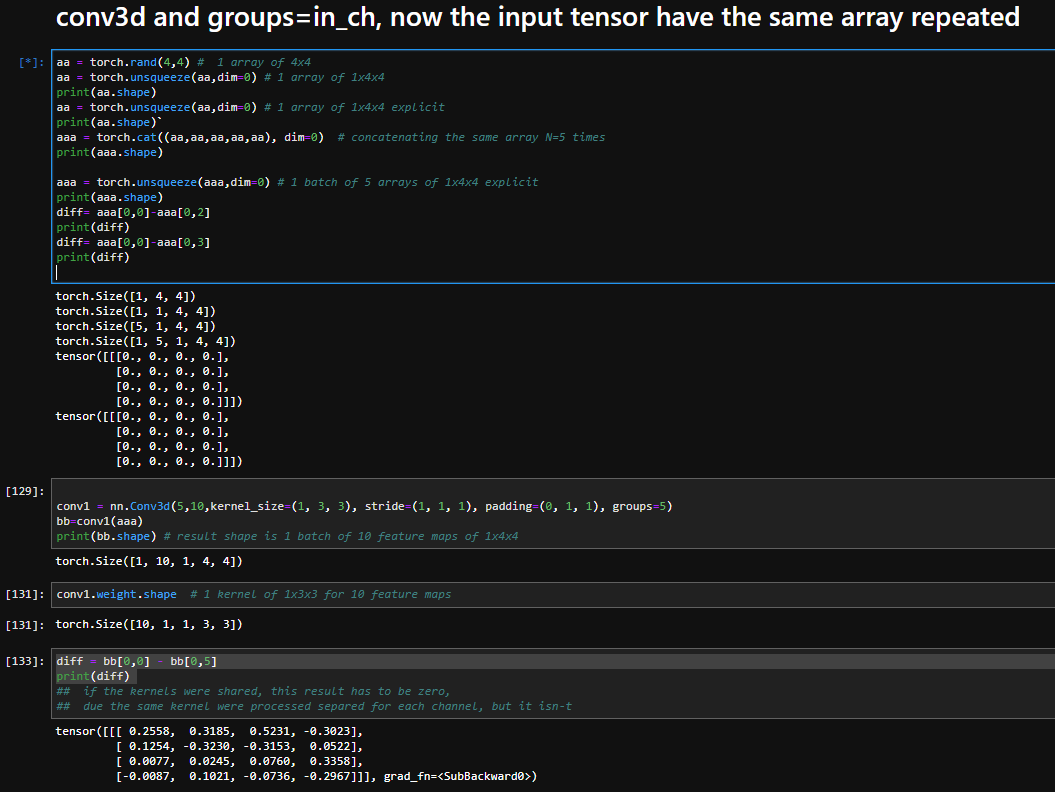
I did a small experiment to confirm this works as I expect it to (and btw, awesome framework where you can just whip something like this together in no time at all ![]() ):
):
import torch
from torch.autograd import Variable
from torch.nn import Conv3d
v = Variable(torch.randn((1, 20, 10, 10)))
v[:, 10:] = 0
c = Conv3d(20, 40, (3, 3), groups=2, bias=False)
print(c.weight.size())
r = c(v)
print(r[:, :20].sum())
print(r[:, 20:].sum())
Result:
(40L, 10L, 3L, 3L)
Variable containing:
14.2016
[torch.FloatTensor of size 1]
Variable containing:
0
[torch.FloatTensor of size 1]
So the input is indeed treated as two separate groups of inputs, each corresponding to a proportionate number of outputs, and (judging from the number of parameters) each group has its own set of weights.
This is, however, not really what I want to do here. I would like all groups to share the same set of weights (i.e., a 20x10x3x3 tensor in the example).
I first tried concatenating several output of a smaller Conv2d layer. It works as expected, but it’s considerably slower (because operations have to be done sequentially?). 10% on my potato-testing-card and 40+% with multiple fast GPUs.
I then tried several combinations of 3d kernels with some unsqueeze and view operations for good measure, but they were just as slow and didn’t produce the result I wanted.
Does anyone have an idea on how to share weights between groups?
For now I’m fine with separate weights (it works quite well), but I would really like to test a theory.
However, blocking resources for several days with an architecture I know is inefficient is not something I’m comfortable with ![]()