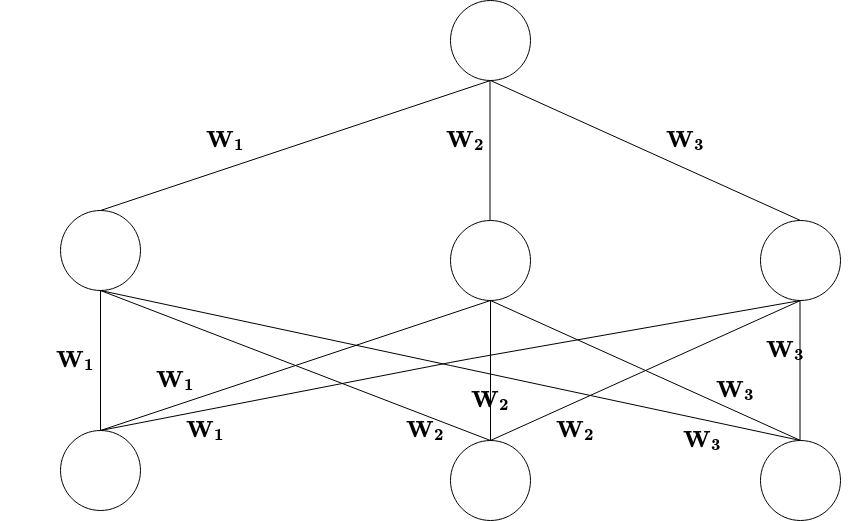
I have an MLP with a particular structure. I would like to share weights between the units of the same layer and between layers as depicted in the following figure :
The way your weights are shared, w1 is multiplied with the first entry, w2 with the second and w3 with the third. THen you sum the three, and this is all the nodes after the first layer. That means that all 3 nodes in the middle here have the same value. Is that expected?
b= 3
n=1000
input=torch.rand(b,n,n)
first_layer_node_1=Relu(w1*w2*w3*input[0])# n by n
first_layer_node_2=Relu(w1*w2*w3*input[1])# n by n
first_layer_node_3=Relu(w1*w2*w3*input[2])# n by n
output_layer=Relu(w1*first_layer_node_1+w2*first_layer_node_2+w3*first_layer_node_3)# n by n