In PyTorch doc, it suggests
torch.optim.lr_schedulerprovides several methods to adjust the learning rate based on the number of epochs.
However, from other sources it looks like the learning rate should be adjusted in every optimization step (batch):
My question is: Should the learning rate in a Learning Rate Scheduler be adjusted per optimization step (batch) or per epoch?
Is there a definitive answer to this, or it depends on the model?
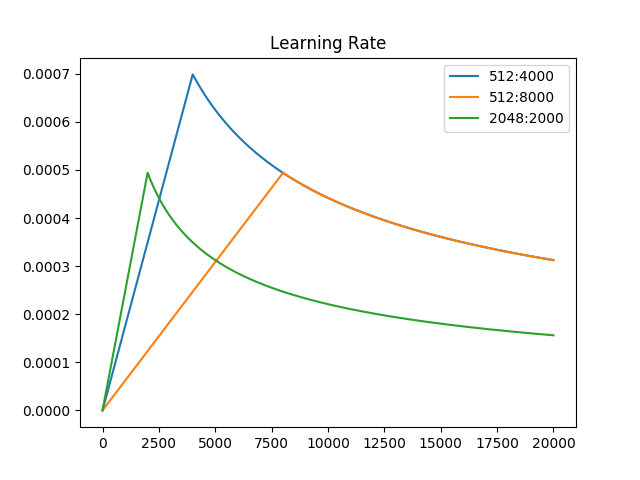
For transformer models, it looks like the learning rate is adjusted by batches. There are a few thousands of steps so it cannot be epochs, right?