Pretty basic, question in the title. I’m practicing on the MNIST dataset on Kaggle.
I’ve read that augmentation is a way to artificially add “new” data to your dataset. However, that doesn’t seem quite true to me, since the augmentations happen randomly and on the fly. This means that every epoch, my network might be seeing a (almost) totally new dataset. I feel like this would lead to underfitting.
That made me wonder about increasing the number of epochs to overcome underfitting, but I surprisingly can’t find a topic on it.
Edit:
at the same number of epochs (50), I lose 20% accuracy on the test set (Kaggle LB) with augmentation.
At 60 epochs, I jump back up to 97% accuracy, which is still 1.5% less accurate than without transformations.
At 70 Epochs, my accuracy drops down to 71% accuracy, which is about 28% worse.
‘Test’ data is unlabelled Kaggle competition data, so I’m not augmenting it… BUT my ‘validation’ set is augmented. I was just trying to figure out if that was bad in a different thread!
Based on the answer in that thread, I removed augmentation from the “validation set” and this is what happened:
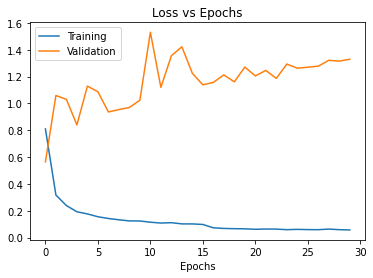
This doesn’t look like overfitting… it looks like the augmentations are straight up BAD for the model.
Whats the probability of the augmentations?
I.e. do you use torchvision.transforms.RandomChoice(transforms) or torchvision.transforms.RandomApply(transforms, p=0.5) to randomize the augmentations?
Since this question was not solved, I wanted to add my two cents.
MNIST is formed in such a way where all the numbers are pointing straight up, they are all viewed straight-on, and there are no affine transformations.
So what the OP did was apply augmentations to the training data which do not exist and cannot exist in the test data. The point of augmentations is to add properties that we do not see directly in the training data due to low training set size, but which are present in the test data.
In this case, augmentation just added noise to the model and decreased performance.
Yes, data augmentation increases training difficulty. You’re feeding the model increasingly varied data each epoch, making it generalize better but possibly delaying convergence. However, it doesn’t mean underfitting — rather, your model is learning a harder, more realistic problem.
Solutions to try:
Reduce augmentation intensity - Your current transforms are quite aggressive. Try smaller rotation angles (±5°) and less dramatic affine transforms
Use learning rate scheduling - Reduce LR as training progresses to help convergence
Add early stopping based on validation accuracy
Try different augmentation probabilities - Apply each transform only 50% of the time
Experiment with fewer simultaneous augmentations - Maybe use only 1-2 transforms per image
The key insight: augmentation is regularization, so you need to balance it with enough training time and proper hyperparameter tuning. Your 60-epoch result suggests augmentation can help, but you need to find the right training duration and intensity.