[Context]
Book: Deep Learning with PyTorch by Eli Stevens, Luca Antiga, and Thomas Viehmann @lantiga
Jupyter Notebook: Part 1 Chapter 7
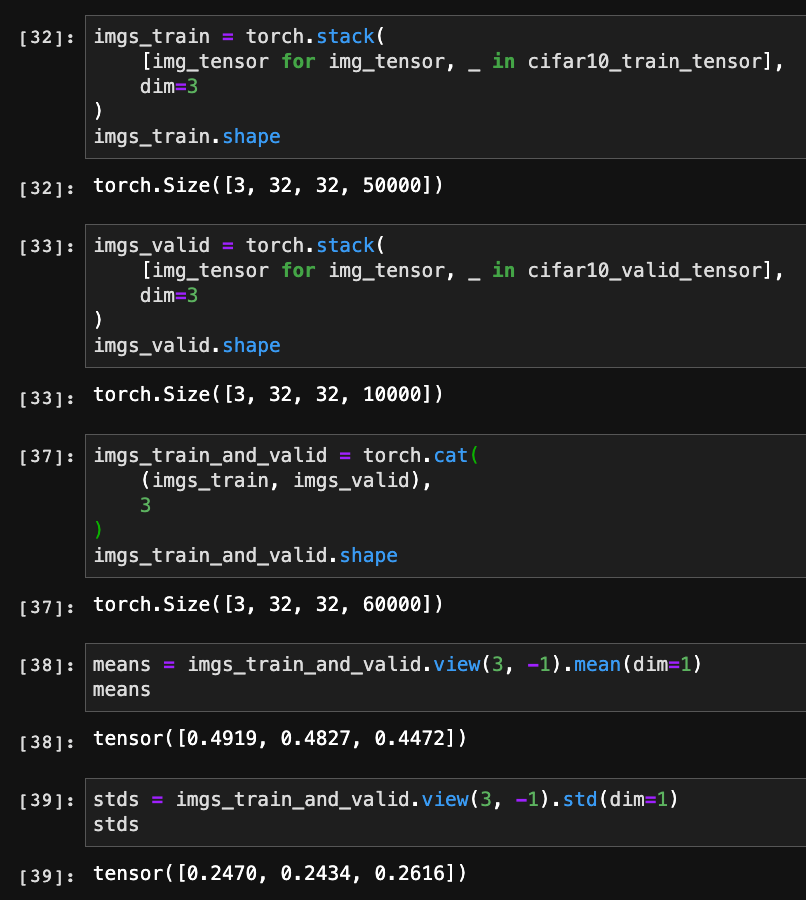
As shown below the means and standard deviations for the RGB channels used in normalization for both the CIFAR10 training and validation datasets are the same.
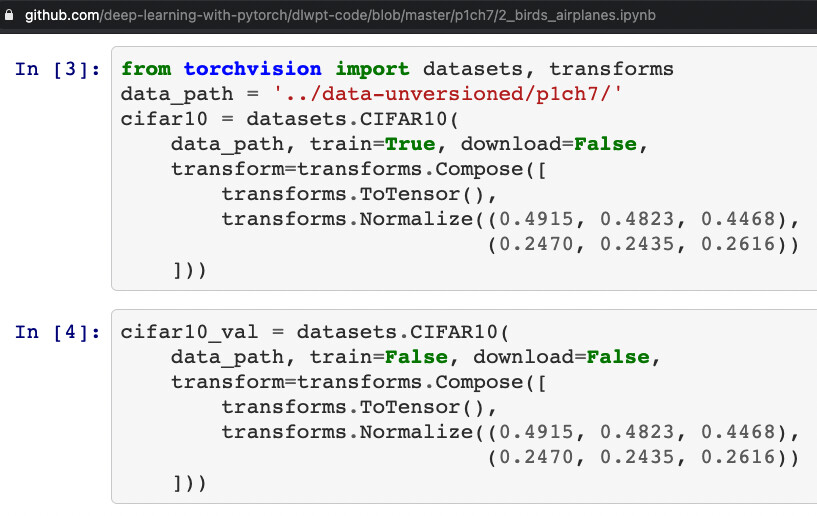
And, they were calculated based on the training set only, as shown in a previous notebook in the same chapter:
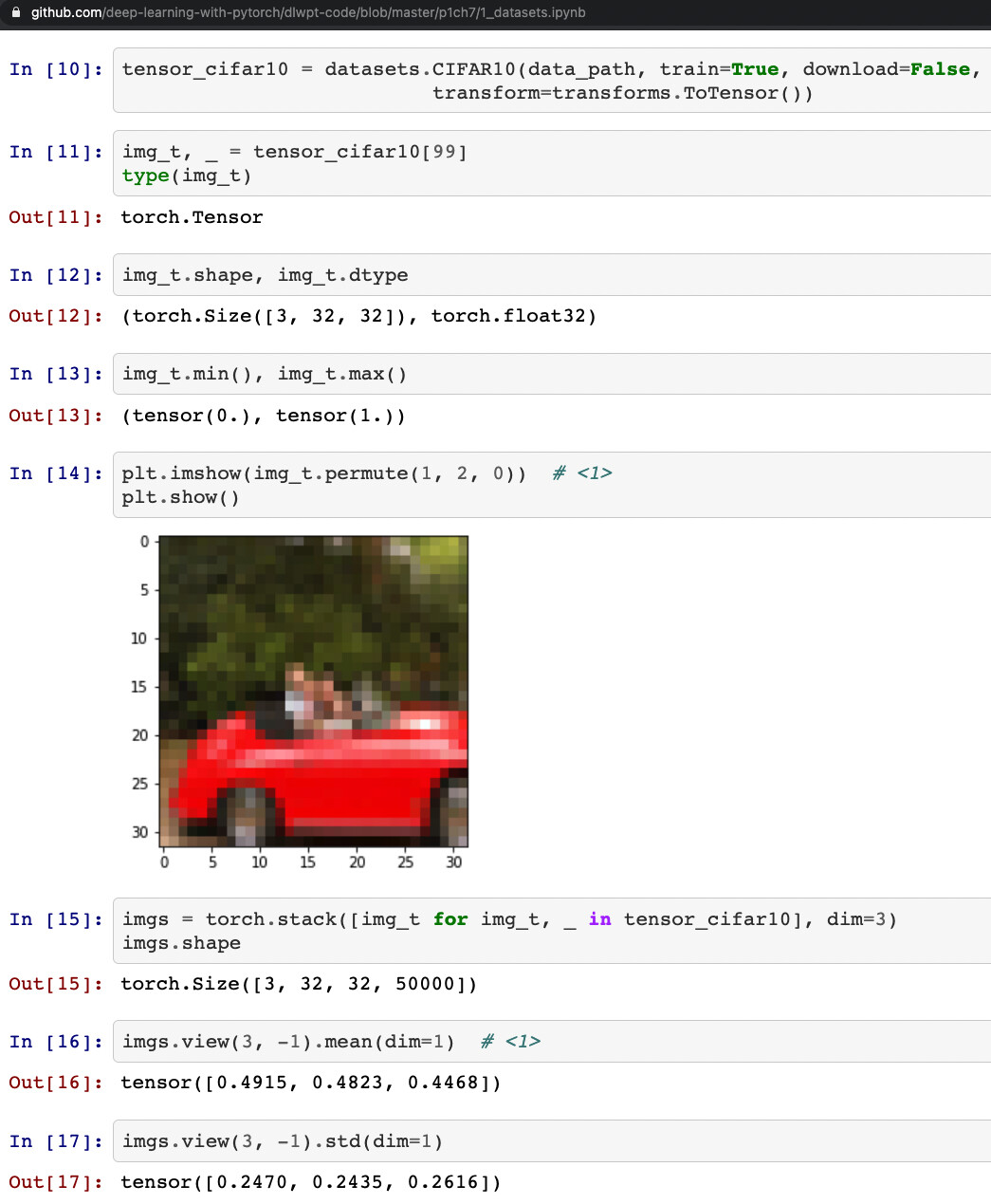
[Question]
Shouldn’t we calculate these means and standard deviations across the entire dataset, i.e. across both the training and validation datasets by stacking them up, as shown below?
Or, The way of “calculating means and stds for normalization using training dataset only” in the book is correct because it is to prevent the information in the validation dataset from “contaminating” normalization, and consequently, affecting the training?