Hi everyone, I am developing a model to perform semantic segmentation. Basically as the title said, I obtain different performances if I change the shuffle parameter of the validation dataloader. Specifically, with shuffle=True the mIoU computed on the validation data is higher than the mIoU computed on the same dataloader but with shuffle=False.
In the following plot you can see the differences:
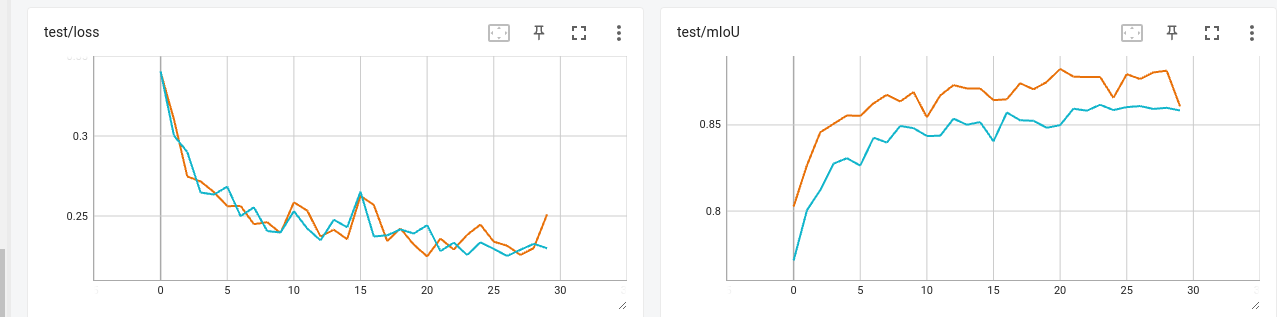
Here, the orange line represents the mIoU and loss computed using dataloader with shuffle=True; viceversa, the blue line represents the same setting, but with shuffle=False.
As you can see there is a big difference between the 2 mIoU plots, even if the losses are more or less the same. Here some relevant line of codes of my train and evaluation loop:
binary_iou = torchmetrics.classification.BinaryJaccardIndex(ignore_index=IGNORE_INDEX_MIOU).to(device)
for epoch in range(epochs):
train_miou = 0
total_loss = 0
# Train
sl_model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device).long()
data, target = random_augmentations(data, target)
outputs = sl_model(data)
loss = criterion(outputs, target)
optimizer.zero_grad()
total_loss += loss.item()
loss.backward()
optimizer.step()
train_miou += binary_iou(torch.argmax(outputs, dim=1), target)
# Evaluation
test_miou = 0
test_loss = 0
sl_model.eval()
for batch_idx, (data, target) in enumerate(val_loader):
data, target = data.to(device), target.to(device).long()
with torch.no_grad():
outputs = sl_model(data)
test_miou += binary_iou(torch.argmax(outputs, dim=1), target)
loss = criterion(outputs, target)
test_loss += loss.item()
I really hope someone can help me, thanks in advance.