I am trying to make a prediction on stock data with a simple LSTM model.
I spilt first 80% data as train set, and last 20% data as test set.
The data shape is like ( batch_size , seq_len , feature_dims)
here is my code for data loader
train_loader=Data.DataLoader(dataset=trainDataset,batch_size=BATCH_SIZE,shuffle=True)
when I set shuffle = false, everything work fine. (Left pics)
However, when I change shuffle to False, the prediction value become weird.(Right pics),the output value will stuck in a very small range.
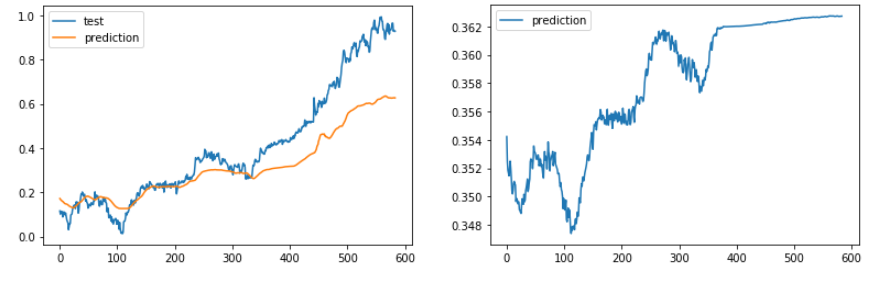
Can anyone give me any suggestion? Thanks!