You don’t need to shuffle the validation and test datasets, since no training is done, the model is used in model.eval() and thus the order of samples won’t change the results.
I forgot to mention that my data sets structure in train/val/test datasets is set this way:
all samples from class 1, followed by all samples from class2 … ,all samples from class n
does your answear holds even in this case ?
Yes, shuffling would still not be needed in the val/test datasets, since you’ve already split the original dataset into training, validation, test.
Since your samples are ordered, make sure to use a stratified split to create the train/val/test datasets.
so shuffle = True or shuffle= false in the val/test loaders would yeild the same results ?
for the second point yes I am sure I have samples from all classes in train/val/test sets.
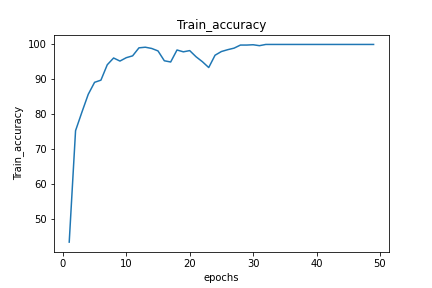
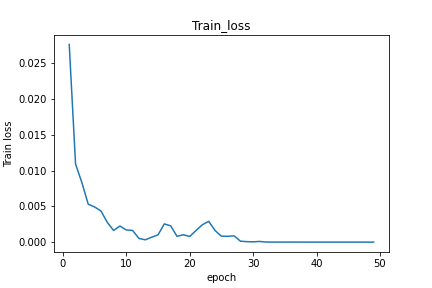
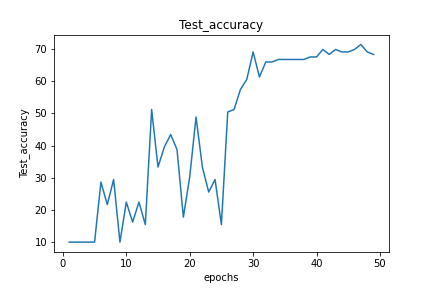
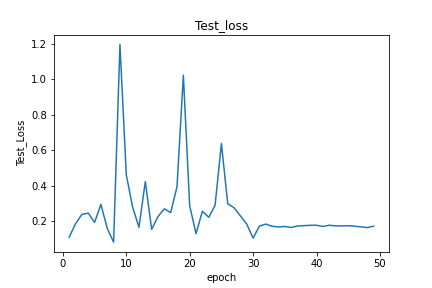
basicly my problem is my test loss function is not decreasing I am getting some thing like this (which I interpret as ovverfitting) :
but on the test loss :
do you have an idea about what it could be (my model is so basic 4 conv layers and 3 linear layers)?
Yes, shuffling the validation/test data will not have any impact on the accuracy, loss etc.
Shuffling is done during the training to make sure we aren’t exposing our model to the same cycle (order) of data in every epoch. It is basically done to ensure the model isn’t adapting its learning to any kind of spurious pattern.
Make sure you aren’t making other errors like this.
Depending on your storage random reads might be more expensive than sequential reads (this should be especially visible using HDDs), which might explain the observed slowdown.
You could profile your storage using e.g. fio as described here.
I am using SSD. I have a dataframe which contains filepath of images I have to read. It is not necessary that image of row 1 is just before the image of row 2 on disk.
I believe there is something else which is taking time.
Hi, I am curious that have you solved your probelm? I think the problem may because of batchnormalization layers, did you use them in your model structure? did you shuffle your training dataset during training?
I’m unsure what =True*=False means, but assume you are asking about both use cases?
If you are tracking running stats, calling model.eval() will use these to normalize the data and shuffling during validation is irrelevant for these layers. However, if you do not track running stats, the inputs will be normalized with their own stats during training and validation, so shuffling matters in both cases (as well as the batch size).