When checking the test set accuracy score i’ve noticed a fluctuating accuracy on each run. Currently i’m using a batch size of 8.
How does batch size and shuffling effect the output of the model? It appears it makes all the difference, if I give the model all one class in a batch it doesn’t perform well.
I have a few questions.
- When the data in the dataloader is shuffled should I experiance a different score each time Its run?
I average 91-92%, but the accuracy is different every time.
-
If I set the dataloaders shuffle to FALSE I get an accuracy score of 50%, a huge reduction from when I shuffle the data. Is this normal?
-
If I manually iterate through each image, convert to tensor, normalize and unsqueeze, I also only get 50% accuracy as when I dont shuffle the dataloader? Is this normal.
I’m sure there is something wrong but can’t for the life of me work it out. Any help appreciated.
EDIT:
I’ve also tried changing the batch size and have realised that this also has an effect on the accuracy.
But I am not backpropogating and have gradients switched off. I thought the way it works is that it predicts on each image in the tensor individually? But I guess this isnt correct?
So how do I infer on a single image if I wanted to?
Or am I completly wrong in my thought pattern?
I’ve run some tests and here are my results, is this expected?#
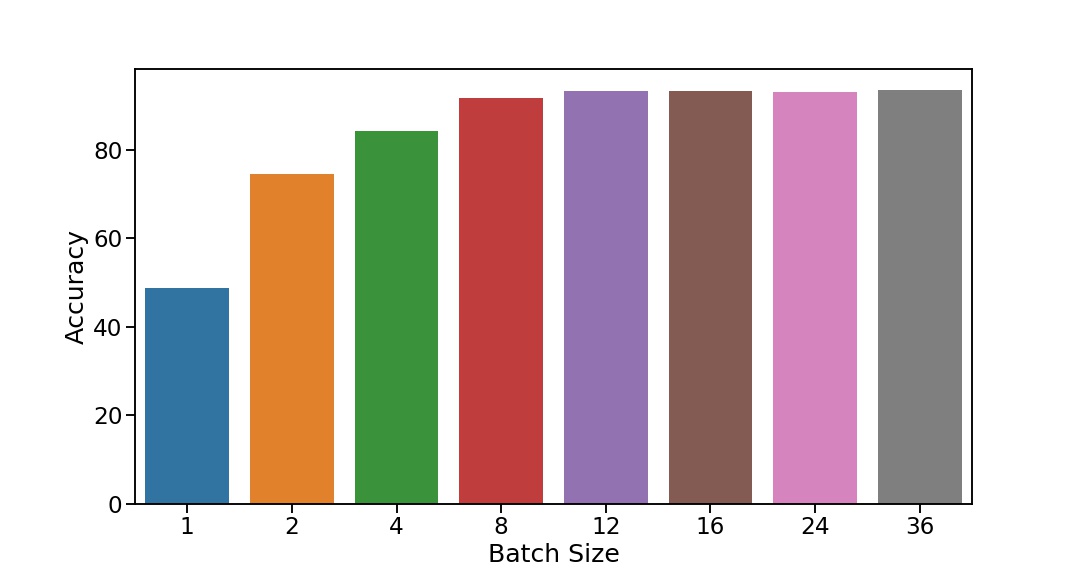
test_location = "/home/lewis/leaf/test/"
#transforms
new_trans_test = transforms.Compose([((image_width_start,image_height_start)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
#load dataset
test = torchvision.datasets.ImageFolder(root=test_location,transform=new_trans_test)
#get data loader
test_loader = torch.utils.data.DataLoader(test, batch_size=batch_size, shuffle=True)
val_total_correct = 0
val_total_checked = 0
for i, data in enumerate(test_loader, 0):
#check batch with no gradients
with torch.no_grad():
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
#get outputs
outputs = net(inputs)
#calculate loss
#calculate accuracy
val_total_correct += torch.sum(torch.argmax(outputs,1) == labels).item()
val_total_checked += len(labels)
print(f"\rAccuracy {round(val_total_correct/val_total_checked*100,2)}% {i+1}/{len(test_loader)} ", end="",flush=True)