To deepen my understanding of Neural Network quantization, I’m re-implementing Post-Training Quantization (PTQ) from scratch with minimal reliance on PyTorch functions. The code can be found here: GitHub Repository.
I followed these steps in my experiments:
- Developed a custom quantizer
- Replaced Linear/Conv layers with custom quantized versions
- Added input and output observers
- Substituted the observers with quantized versions
Weight-Only Quantization:
I successfully built a quantization module that replaces traditional layers with quantized ones and observed how the weights are quantized layer-by-layer. This implementation is available here: Layer-Wise Weight-Only Quantization.
Following this, I moved on to apply quantization to activations. Although I understand that, in practice, scales and zero points are compressed into a single operation:
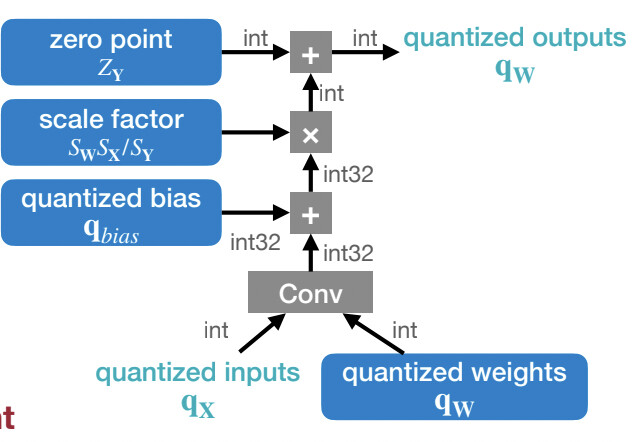
I created a simplified version where scales are handled separately (assuming infinite compute resources). The diagram below illustrates my approach:
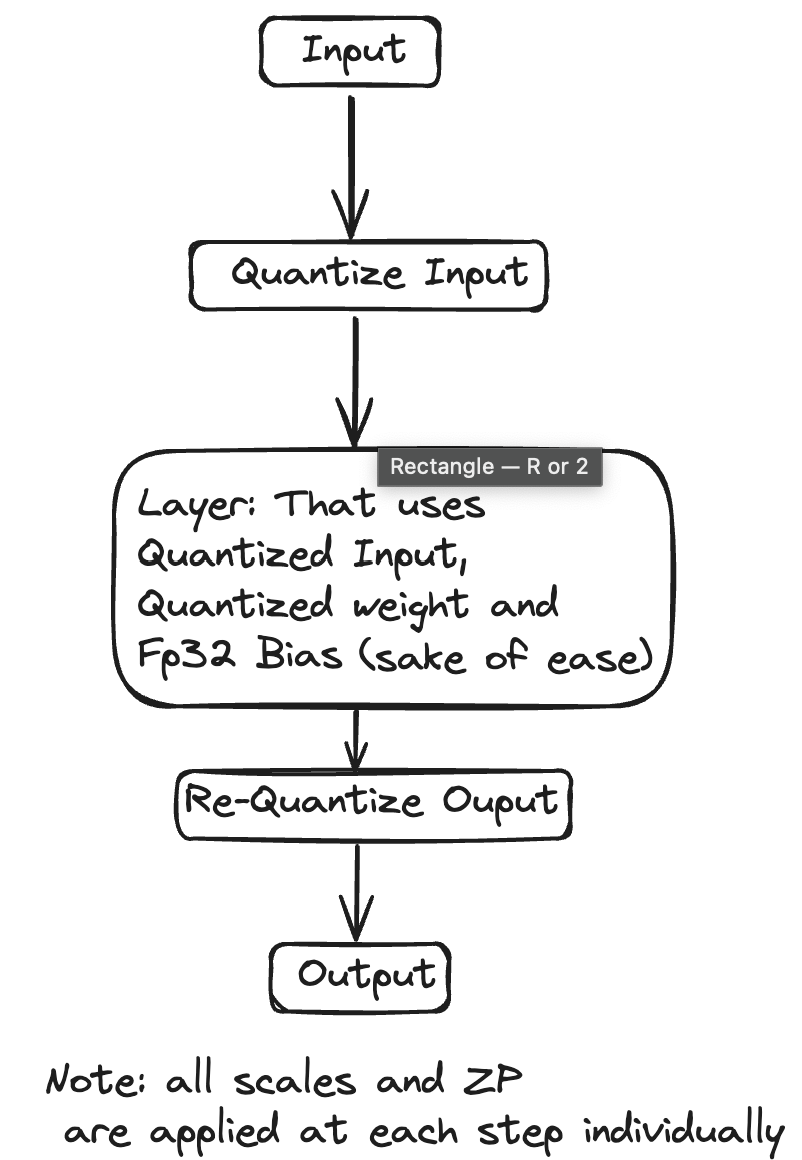
The code for this implementation can be found here: Layer-Wise Weight and Activation Quantization.
Upon activation quantization, the accuracy of the model takes a dives from (~92.3% to 10%). Yet I’m unable to understand why this happens. Any suggestions on why my implementation fails would be really helpful. Thanks in advance.
Thanks,
Sathya