I have trained two models that use the same sequence of image augmentations but in Torchvision and Kornia and I’m observing a significant difference in the performance of these models. I understand that despite fixing random seeds, these augmentations might still be different which might cause some difference in the test accuracy but on average, I assume that both of these models should end with similar accuracy which is not the case.
# PyTorch transformation
train_orig_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
This is the kornia version of the above code
class KorniaAugmentationModule(nn.Module):
def __init__(self, batch_size=512):
super().__init__()
# These are standard values for CIFAR10
self.mu = torch.Tensor([0.4914, 0.4822, 0.4465])
self.sigma = torch.Tensor([0.2023, 0.1994, 0.2010])
self.hor_flip_prob = 0.5
self.jit_prob = 0.8
self.gs_prob = 0.2
self.crop = K.RandomResizedCrop(size=(32, 32), same_on_batch=False)
self.hor_flip = K.RandomHorizontalFlip(p=self.hor_flip_prob, same_on_batch=False)
self.jit = K.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1, p=self.jit_prob, same_on_batch=False)
self.rand_grayscale = K.RandomGrayscale(p=self.gs_prob, same_on_batch=False)
self.normalize = K.Normalize(self.mu, self.sigma)
# Note that I should only normalize in test mode; no other type of augmentation should be performed
def forward(self, x, params=None, mode='train'):
B = x.shape[0]
if mode == 'train':
x = self.crop(x, params['crop_params'])
x = self.hor_flip(x, params['hor_flip_params'])
x[params['jit_batch_probs']] = self.jit(x[params['jit_batch_probs']], params['jit_params'])
x = self.rand_grayscale(x, params['grayscale_params'])
x = self.normalize(x)
return x
This is the only difference between the two models. Rest of the code for training and testing is a common shared code.
These are the plots I obtain for training loss and testing accuracy of the models.
Plots for Training Loss curve and Test Accuracy - Kornia (orange) vs Torchvision (green)
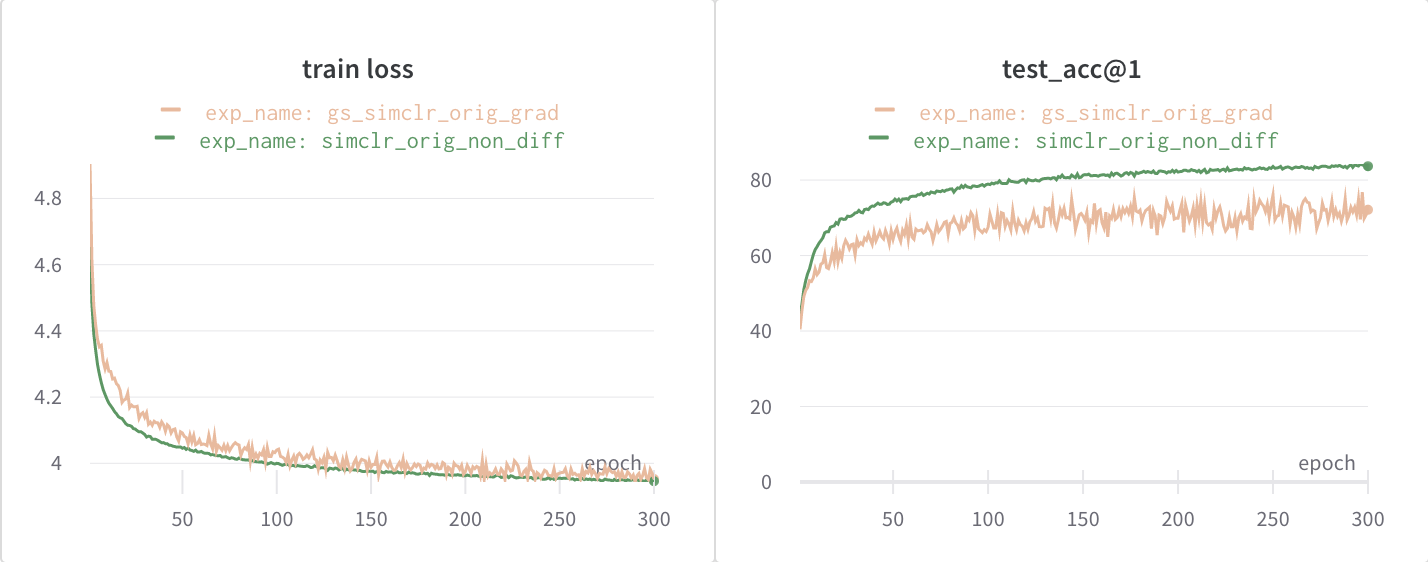
The difference in test accuracies between the two models is nearly ~11% which is very significant.
Is this expected? Could you suggest ways to debug this issue?