import numpy as np
import pandas as pd
import os
from PIL import Image
import torch
import torch.nn as nn
import torch.utils.data as data_utils
from torch.optim.lr_scheduler import ExponentialLR
import torch.nn.functional as F
from torchvision import models, transforms as T
from tqdm import tqdm_notebook
from glob import glob
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style = "darkgrid")
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from ignite.engine import Events, create_supervised_evaluator, create_supervised_trainer
from ignite.metrics import Loss, Accuracy
from ignite.contrib.handlers.tqdm_logger import ProgressBar
from ignite.handlers import EarlyStopping, ModelCheckpoint
target_col = ["target"]
features_col = ["feature1", "feature2", "feature3",...,"feature966"]
def df_to_tensor_w_target_and_features(df):
target = torch.tensor(df[target_col].values, dtype=torch.float32)
features = torch.tensor(df[features_col].values, dtype=torch.float32)
combined = data_utils.TensorDataset(features, target)
return combined
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 64
df = pd.read_csv("./train.dat", sep="\t")
df_test = pd.read_csv("./test.dat", sep="\t")
train_data, val_data = train_test_split(df, random_state = 42, test_size = 0.2, stratify = df["avg_grp_no"])
train = df_to_tensor_w_target_and_features(train_data)
val = df_to_tensor_w_target_and_features(val_data)
test = df_to_tensor_w_target_and_features(df_test)
train_loader = data_utils.DataLoader(train, batch_size=BATCH_SIZE, shuffle=True)
val_loader = data_utils.DataLoader(val, batch_size=BATCH_SIZE, shuffle=False)
test_loader = data_utils.DataLoader(test, batch_size=BATCH_SIZE, shuffle=True)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(966, 1024)
self.fc2 = nn.Linear(1024, 256)
self.fc3 = nn.Linear(256, 10)
self.fc4 = nn.Linear(10, 1)
self.drpout = nn.Dropout(0.2)
def forward(self, x):
x = x.view(-1, 966)
x = F.relu(self.fc1(x))
x = self.drpout(x)
x = F.relu(self.fc2(x))
x = self.drpout(x)
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
model = Net()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr = 0.001)
metrics = { "loss" : Loss(criterion)}
trainer = create_supervised_trainer(model, optimizer, criterion, device = device)
val_eval = create_supervised_evaluator(model, metrics = metrics, device = device)
@trainer.on(Events.EPOCH_COMPLETED)
def compute_and_display(engine):
epoch = engine.state.epoch
metrics = val_eval.run(val_loader).metrics
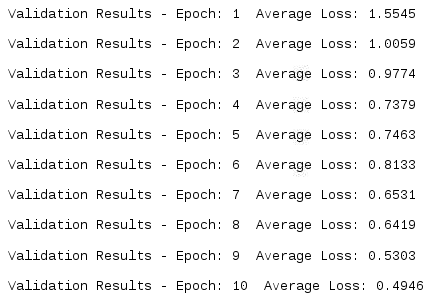
print("Validation Results - Epoch: {} Average Loss: {:.4f} ".format(engine.state.epoch, metrics['loss']))
handler = EarlyStopping(patience = 40, score_function = lambda engine : engine.state.metrics['loss'], trainer = trainer)
val_eval.add_event_handler(Events.COMPLETED, handler)
checkpoints = ModelCheckpoint("models_1", "Model_1", n_saved = 3, create_dir = True, require_empty=False)
trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpoints, {"ANN" : model})
pbar = ProgressBar(bar_format = '')
pbar.attach(trainer, output_transform = lambda x : {"loss" : x})
trainer.run(train_loader, max_epochs = 4)