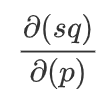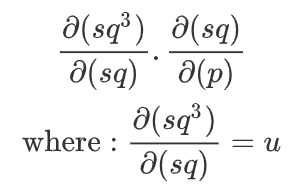Hi guys, very new to PyTorch but have been using successfully on a few small projects until I hit a problem which is summarised in the MWE below. Should this not be returning 6? I am missing something here but am unsure why, and I am certain it is simple.
import torch
p = torch.tensor([1.], requires_grad=True)
class Square(torch.autograd.Function):
@staticmethod
def forward(ctx, target):
ir = torch.pow(target, 2.)
ctx.save_for_backward(target)
return ir
@staticmethod
def backward(ctx, u):
target, = ctx.saved_tensors
return target * 2.
sq = Square.apply(p)
six = sq.pow(3.)
six.backward()
p.grad
This returns tensor([2.]), which is clearly the derivative from square, so why is it not also applying the cube part?
Thank you!!