Hi everyone. I’m building a simple model for a binary classification task on the German Credit Numeric dataset.
I have a numpy array of inputs (24 features), followed by a numpy array of outputs {0,1} as follows:
X:
X[0]: [ 3 6 4 13 2 5 1 4 3 28 3 2 2 2 1 1 0 1 0 0 1 0 0 1]
X shape: (750, 24)
Y:
y[0]: 1
Y shape: (750,)
My model is a simple FC model with ReLU on top:
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
# 24 Features
self.fc1 = nn.Linear(24, 32, device=device)
self.fc2 = nn.Linear(32, 16, device=device)
self.fc3 = nn.Linear(16, 1, device=device)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x[0] # We want the single value only, not a list with a single value
I decided to use BCEWithLogitsLoss(), since I did not put the sigmoid function on the last layer of my model, along with the Adam() optimizer:
loss = nn.BCEWithLogitsLoss()
cnn = LinearModel()
opt = torch.optim.Adam(cnn.parameters(), lr = 1e-3)
epochs = 100
and my train function as follows:
num_correct_train = 0
num_samples_train = 0
num_correct_val = 0
num_samples_val = 0
valAccuracies = []
trainAccuracies = []
trainLosses = []
valLosses = []
avgTrainLosses = []
avgValLosses = []
for epoch in range(1, epochs+1):
# We put the CNN in training mode
cnn.train()
# We iterate over the train set, taking batches of xb, yb.
for xb, yb in zip(Xtrain, ytrain):
xb = torch.from_numpy(xb).float()
yb = torch.tensor(yb).float()
xb, yb = xb.to(device), yb.to(device) # Move them to the GPU
opt.zero_grad() # We empty the gradients
ypred = cnn(xb) # Actual prediction of our model
lTrain = loss(ypred, yb) # We perform a Binary Classification Entropy Loss with Logits between the real value and our prediction
lTrain.backward() # We compute the gradients
opt.step() # Parameters updated -> Single step optimization
# We round the prediction and:
# if == ground truth -> Correct prediction
# if != ground truth -> Wrong prediction
ypred_tag = torch.round(torch.sigmoid(ypred))
if(ypred_tag == yb):
num_correct_train += 1
num_samples_train += 1
trainLosses.append(lTrain.item())
with torch.no_grad():
cnn.eval() # We put our model in evaluation mode for testing the accuracy over the test set
for xb, yb in zip(Xtest, ytest):
xb = torch.from_numpy(xb).float()
yb = torch.tensor(yb).float()
xb, yb = xb.to(device), yb.to(device) # Move them to the GPU
ypred = cnn(xb)
lVal = loss(ypred, yb) # We perform a Binary Classification Entropy Loss with Logits between the real value and our prediction
ypred_tag = torch.round(torch.sigmoid(ypred))
if(ypred_tag == yb):
num_correct_val += 1
num_samples_val += 1
valLosses.append(lVal.item())
avgTrainLosses.append(np.average(trainLosses))
avgValLosses.append(np.average(valLosses))
train_acc = float(num_correct_train)/float(num_samples_train)
trainAccuracies.append(train_acc)
val_acc = float(num_correct_val)/float(num_samples_val)
valAccuracies.append(val_acc)
if (epoch % 5 == 0):
print(f'Epoch {epoch+0:03}:\nTrain Loss: {np.average(trainLosses):.5f} | Train Accuracy: {train_acc:.3f} /----/ Val Loss: {np.average(valLosses):.5f} | Val Accuracy: {val_acc:.3f}')
print("-------------------------------")
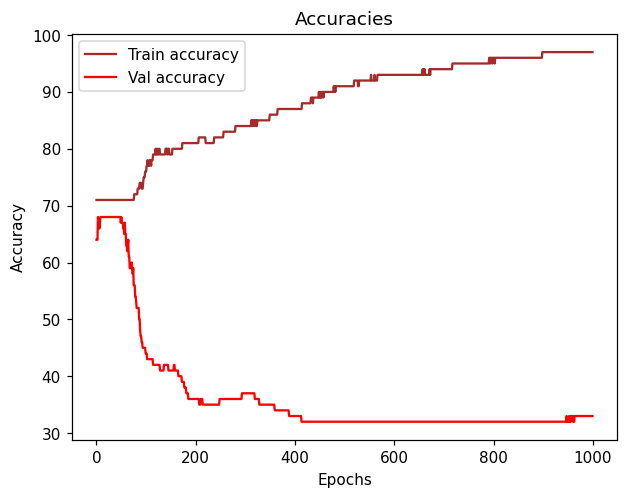
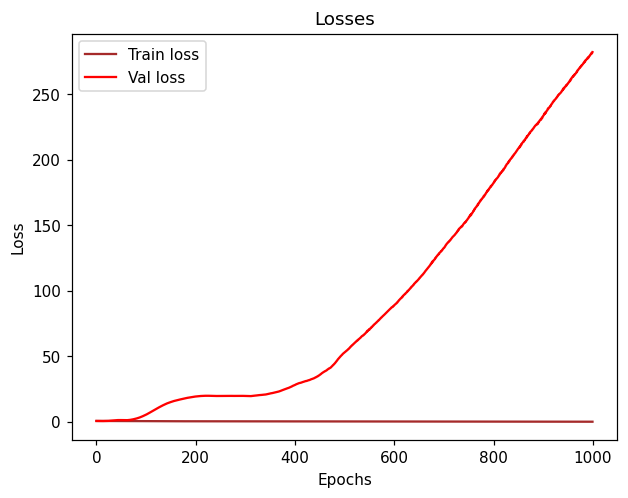
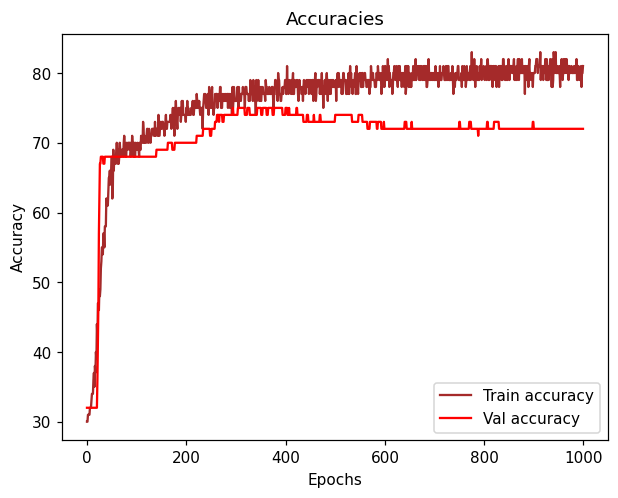
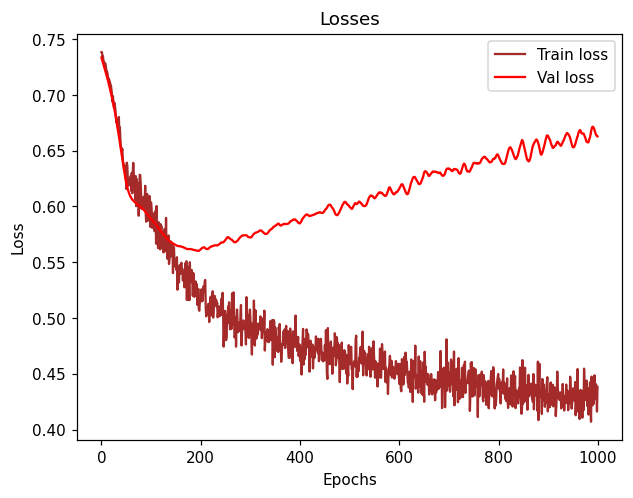
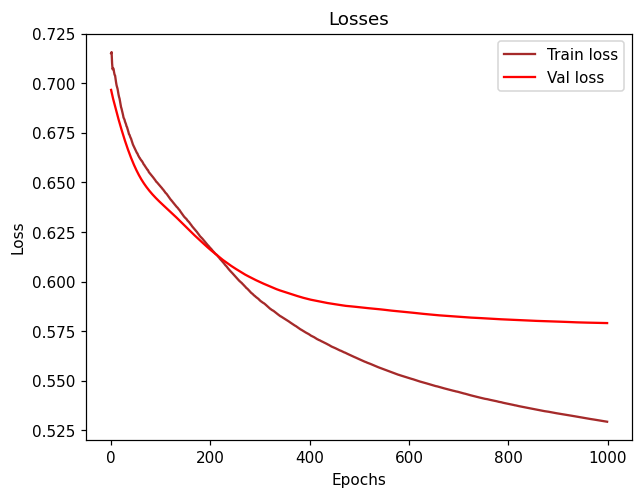
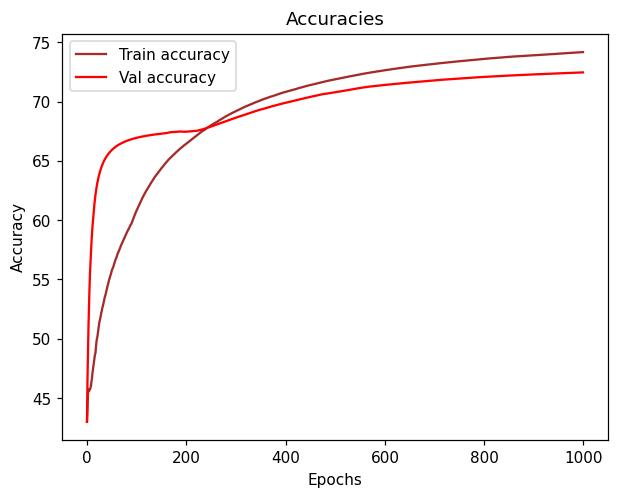
But after training the network for almost 30-40 epochs, it seems like the validation loss and validation accuracy tend to get “flattened” and always keep values around 0.55 (loss) and 0.73 (accuracy).
As for the training loss and accuracy, after 30-40 epochs, they tend to go from 0.47 (Loss) to 0.45 and 0.77 (Accuracy) to 0.78 which is not converging that fast neither.
I don’t get why it doesn’t properly converge faster in the very beginning of the epochs.
Feels like I could train this network for hours and still get a value of accuracy oscillating in the range of 0.73.
Am I doing something wrong?
Thanks!