Hello Frank and thank you so much for answering.
You opened my thoughts about the batch size (I even thought about it, honestly).
I did convert my numpy arrays to two dataloaders as follows:
TrainTensor = TensorDataset(torch.Tensor(Xtrain),torch.Tensor(ytrain))
TrainDataLoader = DataLoader(TrainTensor, batch_size=750, shuffle=True)
TestTensor = TensorDataset(torch.Tensor(Xtest),torch.Tensor(ytest))
TestDataLoader = DataLoader(TestTensor, batch_size=750, shuffle=False)
and my training schedule now takes 250 samples of X (with 24 features) and 250 labels, since I’m iterating like this:
for xb, yb in TrainDataLoader:
and I’m checking for the accuracy as follows:
ypred_tag = torch.round(torch.sigmoid(ypred))
num_correct_train = (ypred_tag == yb).sum().float()
train_acc = torch.round(num_correct_train/yb.shape[0] * 100)
where ypred is the output of my model (250x1) and train_acc is the average between the correct ones and the total number of predictions. I do the same also for the test set.
I did change my ReLU function with LeakyReLU over all the hidden layers in my model.
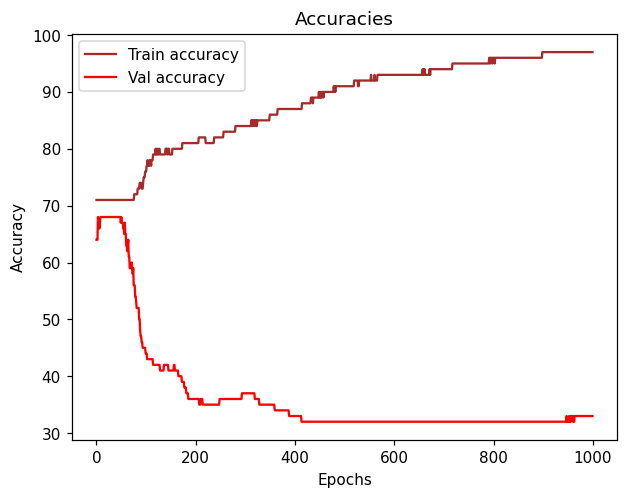
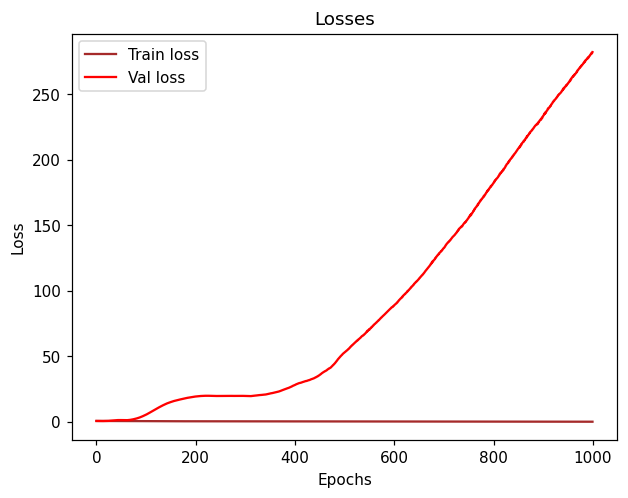
I ran 300 epochs and the final result is as follows:
Epoch 300: Train Loss: 0.40169 | Train Accuracy: 81.000 /----/ Val Loss: 24.78004 | Val Accuracy: 35.000
I really don’t know why my validation loss is so high, I haven’t changed a lot of things except for reshaping my numpy arrays to be dataloaders.
Please note that the train/val accuracy/loss is that specific accuracy/loss for that epoch (in that case 300).
Overall it started with these values (I’m printing every 50 epochs):
Epoch 50: Train Loss: 0.59462 | Train Accuracy: 71.000 /----/ Val Loss: 2.69253 | Val Accuracy: 68.000
I tested it on 1000 epochs and the training accuracy reached 97% and loss 0.1, while validation is still the opposite (32% and 280 loss - which is absurd).