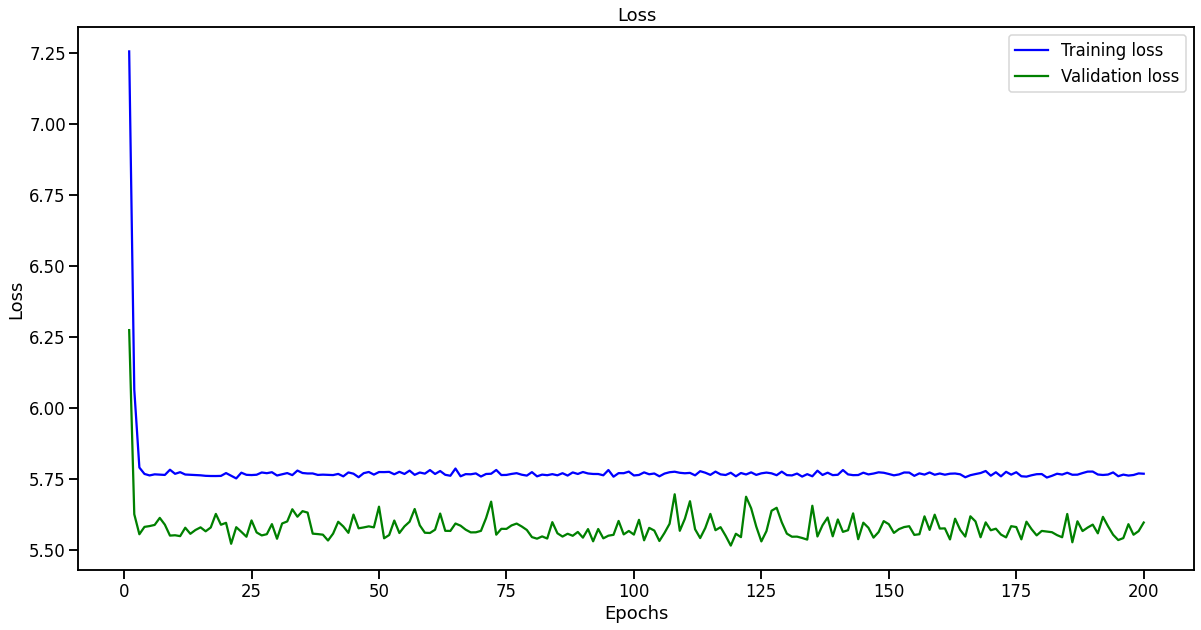
I have this simple gru based encoder decoder model pretty, its the same model as
seq2seq implementation and yet it is over fitting only after 10 epochs.
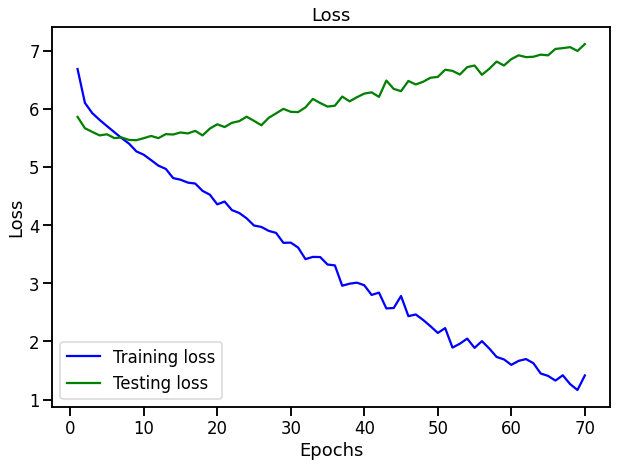
the translation is english to spanish, without pretrained embeddings for either.
I have also used this model for a different dataset, where both src and trg are english, and i was trying to develop some relation between those, and that overfits after 1 epoch.
I dont know what is the problem, This is bugging me for the past 1 week, any help would highly appreciated.
OUTPUT_DIM = eng_vocab_size
INPUT_DIM = esp_vocab_size
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, HID_DIM, ENC_EMB_DIM, ENC_DROPOUT)
dec = Decoder(DEC_EMB_DIM, HID_DIM, OUTPUT_DIM, DEC_DROPOUT)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(enc, dec, device).to(device)
this is the model initialization.