I have a problem where 7 features is collected from some sensors everyday. The sensors are divided into X and y i.e., based on the values of sensors in X we need to predict a value for the sensors in y. I assume the observations depends on the 36 previous observations. My input is now [batchsize, 36, sensor_numbersx, features_dim] and target is [batchsize, sensor_numbersy, 1]. I have a very simple LSTM network as follows:
class LSTMMLP(nn.Module):
def init(self,
input_dim=7,
insties,
output_dim=1,
layers,
lstmdims=16,
nlstmlayers=1):
super(LSTMMLP, self).init()
self.lstm_layers = nn.LSTM(input_dim*insties,
32,
num_layers=1,
batch_first=True
)
self.linear_layers = Sequential(Linear(32, 32),
ELU(inplace=True),
Linear(32, output_dim),
)
def forward(self, x):
_, (hn, _) = self.lstm_layers(x)
out = self.linear_layers(hn[-1])
return out
loss_func = nn.L1Loss(reduction=‘mean’)
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
I have nans in the targets. So, I did loss calculation as follows:
for i, data in enumerate(train_loader):
inputs, labels = data
inputs = inputs.reshape(inputs.shape[0], inputs.shape[1], -1)
outputs = model(inputs)
outputs = outputs.reshape(bsize, -1, 1)
train_loss = loss_func(outputs[~torch.isnan(labels)],
labels[~torch.isnan(labels)]
)
tloss += train_loss.item()
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
I have checked the dimensions and model prameters and grads. They are all updating. But the problem is I am always getting same train and validation loss. It seems to me the model is not learning. Cannot find the error. It will be great if anyone can help please? Thank you all.
Here is my loss curves:
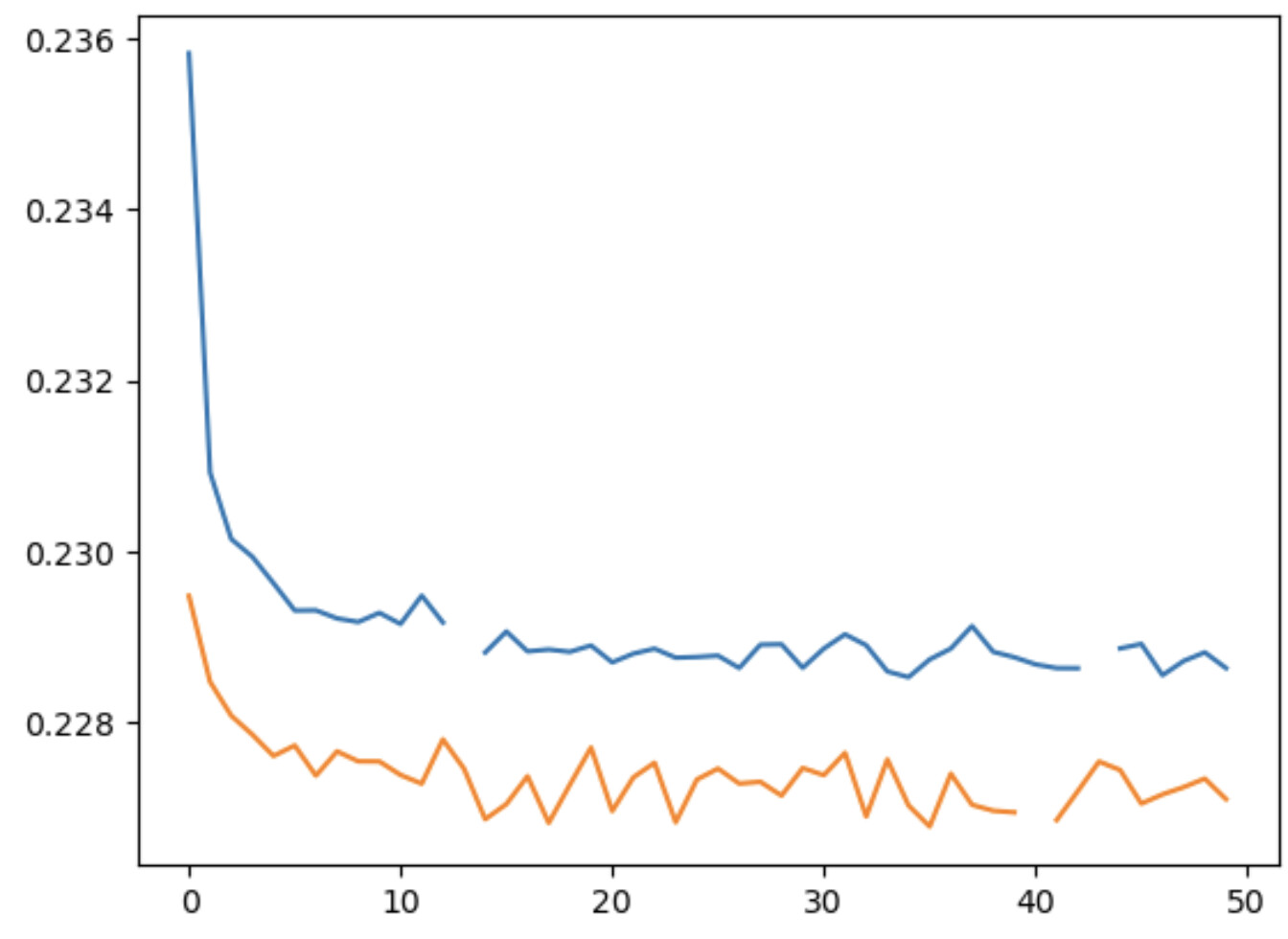
No matter what architecture I use, I get a similar plot