Hi guys,
I have a hard time during training and need help.
I’m trying to make DNN which just simply act as one hot encoding.
So, the input of DNN is just a normal vector. and output of DNN will be the one hot vector of input.
I made DNN with simple linear layers and relu. But, unable to train my model…
What could be the problem in here?
I attach my full code.
class onehot(nn.Module):
def __init__(self, input_dim):
super(onehot, self).__init__()
self.input_dim = input_dim
self.layers = nn.Sequential(
nn.Linear(self.input_dim, 32),
nn.ReLU(inplace=False),
nn.Linear(32, self.input_dim),
)
for m in self.modules():
if isinstance(m, nn.Linear):
torch.nn.init.uniform_(m.weight.data)
def forward(self, x):
return self.layers(x)
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.SGD(encoder_9.parameters(), lr=0.001, momentum=0.9)
encoder_9 = onehot(9).cuda().train()
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(x_list_c1):
# get the inputs; data is a list of [inputs, labels]
inputs = data.cuda()
labels = y_list_c1[i].cuda().float()
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = encoder_9(inputs)
logits = nn.functional.softmax(outputs, dim = -1)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999:
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.6f}')
running_loss = 0.0
print('Finished Training')
training_epoch = 100
My inputs and labels are like this

and training result like this
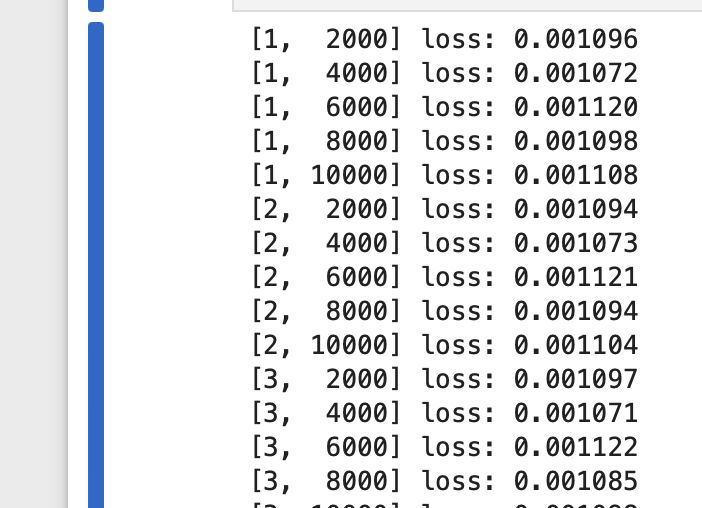
loss does not decreasing… ![]()