I’m currently on Fast.ai mooc, using their fastai V1 built over PyTorch 1.0.
It works like a charm on a 1080Ti + Ryzen 1700X, on Ubuntu 16.04 and Nvidia 410.73.
With the new generation of Nvidia RTX cards offering Tensor Cores, and the possibility of FP16 training via mixed-precision, I got hold of an RTX 2070.
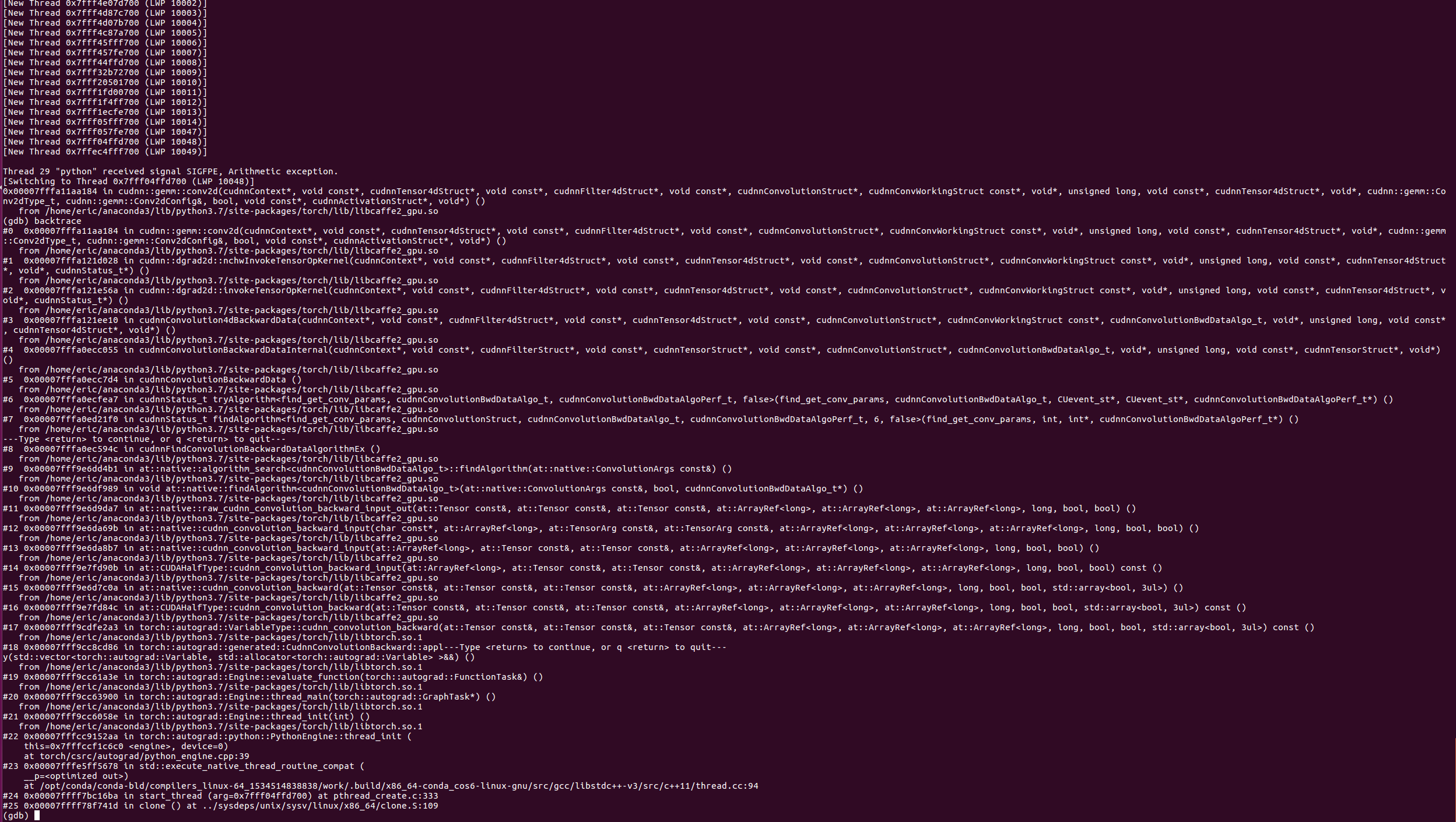
When I try and run my usual Jupyter notebook in mixed precision on the RTX 2070, it crashes the kernel (without a specific error message to track the issue, just “The kernel appears to have died. It will restart automatically.”).
So I thought maybe the first step would be to go down one level to pure PyTorch code and run a “basic test” that would check if/how it triggers the Tensor Cores and FP16 training ?
Is that possible and if so, how should I proceed ?
If your Jupyter Notebook kernel just dies, you could try to download your notebook as a Python script (.py) and run it in a terminal. This will usually yield a better error message.
Note that CUDA operations work asynchronously, so you might need to run your script with:
Thanks for the backtrace.
Skimming through it, could it be you are using torch.float data somewhere in torch.half layers?
Could you post your model definition?
This might take some time to answer as I’m using a script for Cifar10 with a wrn_22() model from the high-level fastai library (like Keras for PyTorch) in the current mooc.
Yes, apex makes sure mixed precision models work fine, i.e. potentially unsafe ops are performed in FP32, while other operations are performed using FP16.
I wanted to post this as the next suggestion, but you were faster.
Were you able to run your script with apex?
I’m not sure, how easy that would be using the fast.ai wrapper.
+1, this works like a charm
Also implements loss scaling, which I found to be necessary
On small models you’ll not see much of an uplift, but on a big imagenet model like resnet18 or resnet50 you should see ~2x the performance (at least on a V100).
Also make sure you have the latest cuDNN, they’re up to 7.3.1 now
Hey, is it necessary to rebuild PyTorch from source or do the “conda” versions work ok?
With my RTX 2080 Ti, I’m hardly seeing any speedup at all (less than 10%) between full and half precision. I built Apex from source with CUDA w/ C++ flags, but mixed it with the “conda” version of PyTorch. maybe that’s bad.
As far as I know the binaries should also work and you will get the most performance benefits if your tensors have a shape of multiples of 8. Could this be the issue in your model/data?
As a late update, I ran a serie of tests with PyTorch + FastaiV1 on Cifar 10/100, comparing a 1080Ti and an RTX 2060 with and without mixed-precision.
It’s not a parfect test (I ran out of time to experiment with max_batch_size with the 1080Ti, as the tests included took over 75-90 hours on my personal PC) but there might be some interesting points.
Also in the article, I put a link to my GitHub repo where you can download each script in Jupyter Notebook to replicate with your own hardware.