I’ve been trying to produce a minimal replication of a text to image U-Net based diffusion model on the HuggingFaceM4/COCO dataset but I’ve been facing an issue where training loss seems to be going down rapidly but upon test time, the model checkpoints don’t seem to be producing text-conditioned images as expected.
I suspect there’s something conceptually wrong with how I’ve built my train loop or how I’m doing inference but I really want to get some more experienced eyes on this to see where I’ve gone wrong.
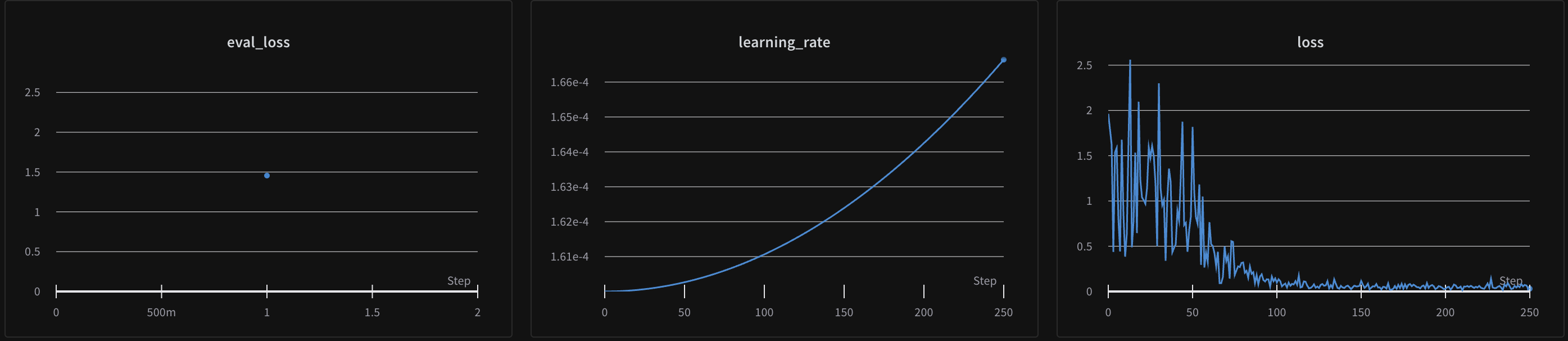
These are the main relevant code files:
import datasets
import transformers
import model
import torch
import os
import collator
import tqdm
from torch.optim import Adam
from torch.cuda.amp import GradScaler, autocast
import sys
sys.path.append("../..")
import common.utils as common_utils
# Environment variable
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Hyperparameters
experiment_name = "dev"
forward_beta = 100.0
forward_num_timesteps = 100
forward_decay_rate = 0.93
num_epochs = 4
batch_size = 12
learning_rate = 4e-3
device = "cuda"
save_steps = 100
do_eval = False
eval_steps = 200
# Outputs folder
common_utils.create_folder("outputs")
# Weights & Biases
common_utils.start_wandb_logging(name=experiment_name, project_name="denoising_diffusion_primitives")
# Device
torch_device = common_utils.get_device(device)
# Tokenizer
tokenizer = transformers.T5TokenizerFast.from_pretrained("t5-small")
text_embedding_model = transformers.T5EncoderModel.from_pretrained("t5-small").to(torch_device)
# Model
unet = model.UNet().to(torch_device)
# Forward/Backward Process
forward_process = model.ForwardProcess(num_timesteps=forward_num_timesteps, initial_beta=forward_beta, decay_rate=forward_decay_rate, torch_device=torch_device)
backward_process = model.BackwardProcess(model=unet, torch_device=torch_device)
# Data
train_ds = datasets.load_dataset('HuggingFaceM4/COCO', '2014_captions')['train']
train_ds = train_ds.remove_columns(['filepath', 'sentids', 'filename', 'imgid', 'split', 'sentences_tokens', 'sentences_sentid', 'cocoid'])
eval_ds = datasets.load_dataset('HuggingFaceM4/COCO', '2014_captions')['validation']
eval_ds = eval_ds.remove_columns(['filepath', 'sentids', 'filename', 'imgid', 'split', 'sentences_tokens', 'sentences_sentid', 'cocoid'])
# Collator
collate_fn = collator.Collator().collate
train_dataloader = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True, collate_fn=collate_fn, num_workers=8, drop_last=True)
eval_dataloader = torch.utils.data.DataLoader(eval_ds, batch_size=batch_size, shuffle=True, collate_fn=collate_fn, num_workers=8, drop_last=True)
# Optimizer and Scheduler
optimizer = Adam(list(unet.parameters()), lr=learning_rate)
scheduler_steps = num_epochs * len(train_dataloader)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=learning_rate, total_steps=scheduler_steps, pct_start=0.25)
# GradScaler for mixed precision training
scaler = GradScaler()
# Print the number of trainable parameters in both the unet and the downsample text embedding layer
num_trainable_params_unet = sum(p.numel() for p in unet.parameters() if p.requires_grad)
print(f"Number of trainable parameters in UNet: {num_trainable_params_unet}")
# Train loop
for epoch in tqdm.tqdm(range(num_epochs)):
print("Epoch:", epoch)
for i, batch in tqdm.tqdm(enumerate(train_dataloader), total=len(train_dataloader)):
# Get data
image = batch["image"].to(torch_device)
text = batch["sentences_raw"]
# Forward Noising Step
timestep = torch.randint(0, forward_num_timesteps, (batch_size,)).to(torch_device)
noised_image = forward_process.sample(image=image, timestep=timestep)
noise_added = noised_image - image
# Backward Generation Step
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True).to(torch_device)
outputs = text_embedding_model(**inputs)
text_embedding = outputs.last_hidden_state
mean_text_embedding = text_embedding.mean(dim=1)
with autocast():
predicted_noise = backward_process.predict(image=noised_image, text=mean_text_embedding)
# Loss
loss = torch.nn.functional.mse_loss(noise_added, predicted_noise)
# Backward pass with gradient scaling
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
scheduler.step()
# Log to Weights & Biases
common_utils.log_wandb({
"loss": loss.item(),
"learning_rate": scheduler.get_last_lr()[0],
})
# Save checkpoint every `save_steps` steps
if i % save_steps == 0 and i != 0:
torch.save({
'epoch': epoch,
'model_state_dict': unet.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, os.path.join("./outputs/", f"checkpoint_{epoch}_{i}.pt"))
# Evaluate every `eval_steps` steps
if do_eval and i % eval_steps == 0:
print("Evaluating...")
unet.eval()
eval_losses = []
for j, eval_batch in tqdm.tqdm(enumerate(eval_dataloader), total=len(eval_dataloader)):
# Get data
eval_image = eval_batch["image"].to(torch_device)
eval_text = eval_batch["sentences_raw"]
# Forward Noising Step
eval_timestep = torch.randint(0, forward_num_timesteps, (batch_size,)).to(torch_device)
eval_noised_image = forward_process.sample(image=eval_image, timestep=eval_timestep)
eval_noise_added = eval_noised_image - eval_image
# Backward Generation Step
eval_inputs = tokenizer(eval_text, return_tensors="pt", padding=True, truncation=True).to(torch_device)
eval_outputs = text_embedding_model(**eval_inputs)
eval_text_embedding = eval_outputs.last_hidden_state
eval_mean_text_embedding = eval_text_embedding.mean(dim=1)
with autocast():
eval_predicted_noise = backward_process.predict(image=eval_noised_image, text=eval_mean_text_embedding)
# Loss
eval_loss = torch.nn.functional.mse_loss(eval_noise_added, eval_predicted_noise)
eval_losses.append(eval_loss.item())
# Log the mean eval loss over the entire evaluation loop to Weights & Biases
common_utils.log_wandb({
"eval_loss": sum(eval_losses) / len(eval_losses),
})
unet.train()
# Save checkpoint every epoch
torch.save({
'epoch': epoch,
'model_state_dict': unet.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, os.path.join("./outputs/", f"checkpoint_{epoch}.pt"))
# End logging
common_utils.end_wandb_logging()
Model/Forward/Backward process code
import torch
from torch import nn
import numpy as np
class ForwardProcess():
"""Adds noise to an image in a forward process."""
def __init__(self, num_timesteps: int = 100, initial_beta: float = 0.2, decay_rate: float = 0.98, torch_device: torch.device = torch.device("cuda")) -> None:
"""Initialize the forward process.
Args:
num_timesteps: Number of timesteps in the diffusion process.
initial_beta: Initial beta value. This is a hyperparameter that we tune.
It represents what is the standard deviation of the noise that we add to
the images at the first timestep (which has maximum noise).
decay_rate: Decay rate for each subsequent beta.
"""
self.betas = self.generate_betas(num_timesteps, initial_beta, decay_rate).to(torch_device)
def generate_betas(self, num_timesteps: int, initial_beta: float, decay_rate: float) -> torch.Tensor:
"""Generate an array of betas for diffusion.
Q: Why is betas going from high values to low?
A: It follows the timesteps of the backward process which starts from lots of
noise and gradually removes noise.
Args:
num_timesteps: Number of timesteps in the diffusion process.
initial_beta: Initial beta value.
decay_rate: Decay rate for each subsequent beta.
Returns:
A torch.Tensor containing generated betas.
"""
# Create an array of indices
indices = np.arange(num_timesteps)
# Compute the betas in a vectorized manner
betas = initial_beta * (decay_rate ** indices)
# Convert to a torch tensor and return
return torch.tensor(betas, dtype=torch.float32)
def sample(self, image: torch.Tensor, timestep: torch.Tensor) -> torch.Tensor:
"""Sample from the forward process at a specific timestep.
Args:
image: The image to noise.
timestep: The timestep to sample at.
"""
noise_std = torch.sqrt(self.betas[timestep])
noise = torch.randn_like(image) * noise_std.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1)
noised_image = image + noise
return noised_image
class BackwardProcess():
"""Generates an image from a noised image in a backward process."""
def __init__(self, model, torch_device=torch.device("cuda")) -> None:
"""
Initialize the backward process.
Args:
model: The model to be used in the backward process.
"""
self.unet = model
self.torch_device = torch_device
def predict(self, image: torch.Tensor, text: torch.Tensor) -> torch.Tensor:
"""Predict the amount of noise
TODO: You can also embed timestep into the upsampling.
Args:
image (torch.Tensor): The image to denoise. Shape is (batch_size, channels, height, width).
text (torch.Tensor): The text embedding. Shape is (batch_size, embedding_dim).
Returns:
torch.Tensor: Predict the amount of noise. Shape is (batch_size, channels, height, width).
"""
output = self.unet(image, text)
return output
class UNet(nn.Module):
"""This UNet is the main workhorse of the backward denoising process."""
def __init__(self):
"""Initialize the UNet model."""
super(UNet, self).__init__()
self.enc1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool1 = nn.MaxPool2d(2)
self.enc2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool2 = nn.MaxPool2d(2)
self.enc3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU()
)
self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = nn.Sequential(
nn.Conv2d(256, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU()
)
self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = nn.Sequential(
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 3, kernel_size=1)
)
self.embedding_projector = nn.Linear(512, 256)
def forward(self, x: torch.Tensor, text_embedding: torch.Tensor) -> torch.Tensor:
"""Forward pass through the UNet model.
Args:
x (torch.Tensor): The input tensor, typically an image.
text_embedding (torch.Tensor): The text embedding tensor.
Returns:
torch.Tensor: The output tensor after passing through the model.
"""
# Encode
enc1 = self.enc1(x)
enc2 = self.enc2(self.pool1(enc1))
enc3 = self.enc3(self.pool2(enc2))
# Project the text embedding to 256 dimensions
text_embedding = self.embedding_projector(text_embedding)
# Expand text embedding into same dim as enc3
text_embedding = text_embedding.unsqueeze(-1).unsqueeze(-1).expand(enc3.shape)
# Concatenate enc3 and text_embedding
enc3 = enc3 + text_embedding
# Decode
dec2 = self.dec2(torch.cat([self.up2(enc3), enc2], dim=1))
dec1 = self.dec1(torch.cat([self.up1(dec2), enc1], dim=1))
return dec1
from typing import List, Dict, Any
import torchvision
import torch
import random
class Collator():
"""A class used to collate batches of data."""
def __init__(self):
"""Initialize the Collator class with a transform that resizes images and converts them to tensors."""
self.transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((480, 640)), # Resize images to 480 height and 640 width
torchvision.transforms.Lambda(lambda x: x.convert('RGB')), # Convert images to 3 channels (RGB)
torchvision.transforms.ToTensor() # Convert images to tensors
])
def collate(self, batch: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Collate a batch of data by transforming images and selecting a random sentence from each item.
Args:
batch (list): A list of items, each containing an image and sentences.
Returns:
dict: A dictionary containing transformed images and a list of randomly selected sentences.
"""
images = [self.transform(item['image']) for item in batch]
images = torch.stack(images, dim=0)
collated = {
"image": images,
"sentences_raw": [random.choice(item['sentences_raw']) for item in batch]
}
return collated
import torch
import transformers
import model
import utils
import tqdm
import sys
sys.path.append("../..")
import common.utils as common_utils
# Hyperparameters
device = "cpu"
# Inputs
model_checkpoint = "./outputs/checkpoint_0_100.pt"
# Device
torch_device = common_utils.get_device(device)
# Text Embedding
tokenizer = transformers.T5TokenizerFast.from_pretrained("t5-small")
text_embedding_model = transformers.T5EncoderModel.from_pretrained("t5-small").to(torch_device)
# Initialize model and load checkpoint
unet = model.UNet().to(torch_device)
unet.load_state_dict(torch.load(model_checkpoint, map_location=torch_device)["model_state_dict"])
backward_process = model.BackwardProcess(model=unet, torch_device=torch_device)
# Get pure Gaussian noise image
noised_image = torch.randn((1, 3, 480, 640)).to(torch_device) # 480 by 640 RGB image of pure Gaussian noise
# Get text prompt
text = "a man riding a red motorcycle"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True).to(torch_device)
with torch.no_grad():
outputs = text_embedding_model(**inputs)
text_embedding = outputs.last_hidden_state
mean_text_embedding = text_embedding.mean(dim=1)
# Denoise image
for i in tqdm.tqdm(range(100)):
with torch.no_grad():
predicted_noise = backward_process.predict(image=noised_image, text=mean_text_embedding)
noised_image = noised_image - predicted_noise
if i % 10 == 0:
utils.save_image(noised_image, f"./outputs/image_{i}.png")
utils.save_image(noised_image, "./outputs/image_final.png")